1/10成本、Opus 4.7级表现。
Cursor模型更新,最新版本已来到 Composer 2.5。
稍微一翻 Cursor 公告,两件事挺有意思:
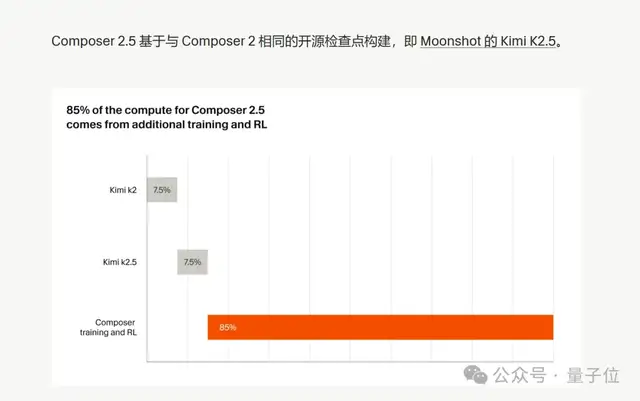
一是 Cursor 这回学老实了,新模型“套”了 Kimi 不再藏着掖着,连具体用了多少都标得清清楚楚。
(Cursor:Kimi 打底,自家额外训练 + RL 占了 85% 的总算力)
二是马斯克原地上演变脸。之前 Cursor 陷入“套壳风波”时,他在旁边煽风点火,现在却十分卖力地帮忙站台:
都给我去用 Cursor 新模型。
网友:老马你让我感到陌生(doge)。

别想多了,其实这是因为 Cursor 和马斯克达成了算力合作——
Composer 2.5 部分训练是在 Colossus 2 上完成的;另外,Cursor 还正在和 SpaceXAI 合作,从零开始训练一个规模明显更大的模型。

好好好,新模型刚来,下一代模型的“饼”又吃上了,看来 Cursor 真是铆足了劲想搞自研(具体原因下文详聊)。
不过远的咱够不着,先看眼前这个实在的——Composer 2.5 本身亮点也很足。
1/10 成本、Opus 4.7 级表现,而且发布后首周还给你双倍用量。
好家伙,这几个词一甩出来,经常用模型的朋友谁不沸腾了。
但问题是,Cursor 新模型真有这么顶吗??
顶不顶目前咱不好说,反正测评成绩挺亮眼。
据 Cursor 介绍,“它更擅长在长时间运行的任务中持续工作,更可靠地遵循复杂指令,协作体验也更加顺畅。”
这些表现反映到具体数字上就是,其性能水平整体接近 Claude Opus 4.7。
- Terminal-Bench 2.0(终端/命令行任务):69.3% VS 69.4%,几乎持平;
- SWE-Bench Multilingual(多语言工程问题):79.8% VS 80.5%,差距微弱;
- CursorBench v3.1(高难度编程任务):63.2% VS 最高配 64.8%,差距微弱。

能和 Opus 4.7 相提并论,常用模型的人都知道这里头的含金量了。

而且除了在更高难度的任务上训练之外,他们还改进了模型在沟通风格和投入级别校准(什么时候该出多大力)等行为层面的表现。
听起来有点抽象,但 Cursor 表示:
这些维度很难通过现有基准充分反映,但我们发现,它们对实际使用效果非常重要。
那么,Composer 2.5 真实能力如何呢?
鉴于目前 Cursor 免费用户只能体验 Auto 模式(虽然上架了但是选不了),所以咱先看一波网友的反馈。
先插一嘴,Composer 模型速度是真快啊,甭管是哪一个版本,用起来歘歘歘的。
OK,回归正题。
目前一圈扒下来,感觉 Composer 2.5 反馈还不错??
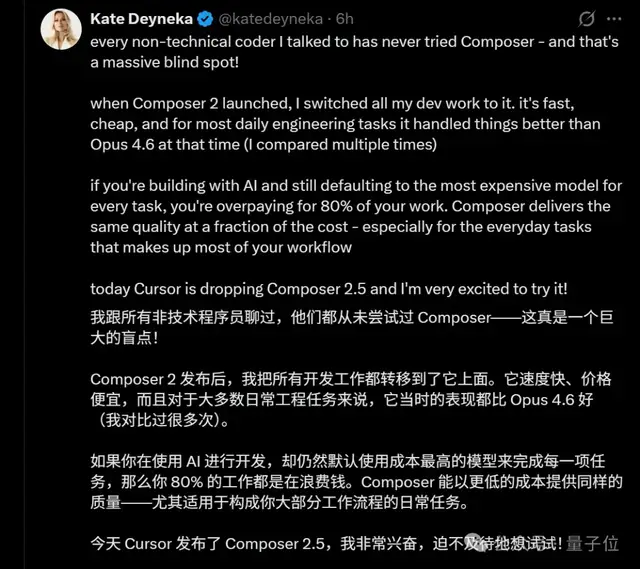
Snapchat 前机器学习工程师激情发帖称,自从 Composer 2 发布后,她就把绝大多数开发工作搬到了 Cursor 上面。
而且还甩出了一句颇有暴论味道的话:
如果你在使用 AI 进行开发,却仍然默认使用成本最高的模型来完成每一项任务,那么你 80% 的工作都是在浪费钱。
图像生成初创公司 LetzAI 的 CEO 也有类似感受。他在体验新模型几小时后表示:
以前可能会对 AI 的方案挑三拣四、反复修改,但这次因为 Composer 2.5 做得太好太快,自己直接“躺平认了”。
没什么可挑剔的,就这么办吧。
想必你也发现了,除了模型能力之外,他们提到了另一个重要关键词:价格。
Composer 2.5 的价格为每百万输入 token 0.50 美元、每百万输出 token 2.50 美元。
此外,还有一个智能水平相同但速度更快的变体,价格为每百万输入 token 3.00 美元、每百万输出 token 15.00 美元。
p.s. 与 Composer 2 一样,fast 是默认选项。
这个价格怎么说呢?也就是 Opus 4.7 的 1/10 吧。
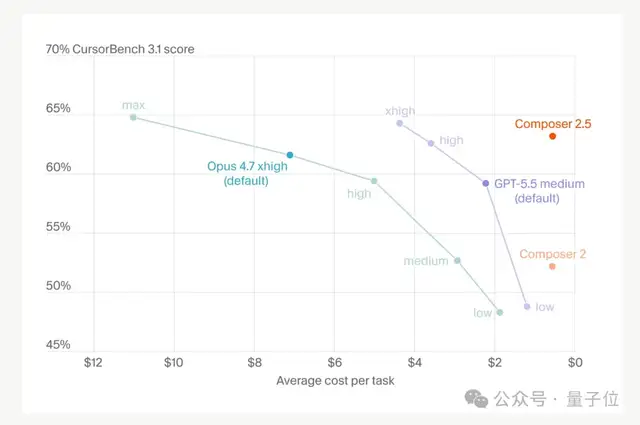
1/10 成本、Opus 4.7 级表现,如果效果真如测评和网友所言,那绝对是真香了。
Kimi 打底,还做了这些训练改进
那么 Composer 2.5 这次是如何实现性能“飞跃”(至少是表面上)的呢?
虽说是有 Kimi 打底,但好歹贴的是“Cursor 自研模型”的标签,这背后多多少少总得有自研吧。
Cursor:别说,我还真有。

回到模型本身,Cursor 这回在训练栈上做了不少改进,主要围绕两个方向:
模型智能和易用性。
具体则有三点:
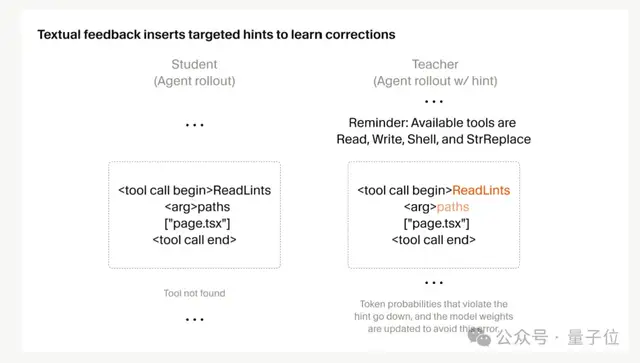
第一,给 RL 训练加了“定向反馈”
以前 RL 奖励是基于整条轨迹算的,rollout 动辄几十万 token,模型很难知道自己究竟是哪一步搞砸了——最终奖励只能告诉你“出问题了”,但具体错在哪儿,信号噪声特别大。
Cursor 的解法是:哪里不对就在哪里直接喂反馈。
举个例子,模型在某一轮调用了一个不存在的工具,收到报错后继续干别的。几百次调用里就这一次错,对最终奖励基本没影响。
但 Cursor 会在出错那一轮的上下文里插一句“Reminder: Available tools…”并附上可用工具列表,由此得到一个新的“教师”概率分布。
如此一来,错误工具的概率被压下去,有效替代项的概率被抬上来,然后让学生模型向这个分布靠拢就行。
这套方法在 Composer 2.5 里被用在了多种行为上,从编码风格到沟通方式都有。
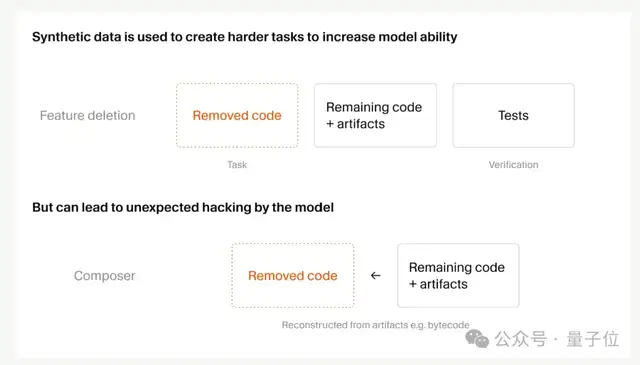
第二,合成数据规模翻了 25 倍
RL 训练几轮下来,Composer 已经能解决大部分训练题了,怎么继续提升?
答案是动态生成更难的任务。
其中一个玩法叫“功能删除”——给智能体一个带测试的代码库,让它删掉某个特定功能但保证代码库还能跑,然后任务就是把这个功能重新实现出来,测试就是奖励信号。
不过任务一多,奖励作弊也跟着来了。
Cursor 发现 Composer 2.5 会整一些离谱操作,比如逆向 Python 类型检查缓存,找出被删的函数签名;甚至反编译 Java 字节码,重建第三方 API。
好在都被监控工具抓到了,但也算提了个醒——大规模 RL 得更小心。
第三,底层训练做了优化
Cursor 用的是带分布式正交化的 Muon,并把通信做成异步——一个任务等通信时,优化器接着推进其他任务,让网络和计算重叠起来。
最终在 1T 模型上,优化器每步只要 0.2 秒。
另外,针对 MoE 模型,他们把非专家权重和专家权重的 HSDP 布局拆开了:非专家权重小,FSDP 组就窄一点,单节点内搞定;专家权重大,就用更宽的分片网格。
这样彼此独立的并行维度也能重叠,比如 CP=2 和 EP=8 可以在 8 个 GPU 上跑,而不用占 16 个。
总之,从训练信号到数据规模,再到底层并行,Cursor 这次是全栈都动了一遍。
One More Thing
Cursor 为啥这么拼搞自研?其实从它和 Anthropic 的微妙关系里就能管中窥豹。
刚好最近看了姚顺宇(不是腾讯那个)做客张小珺播客的那期节目,这位 Anthropic 前员工的观察,正好能说明问题:
Cursor 最早是踩着 Claude 的肩膀火起来的。开发者社区里口口相传的好用,背后很大一部分功劳来自 Claude 模型本身。那段时间 Cursor 和 Anthropic 是典型的“鱼水关系”,一个出模型,一个出产品,各赚各的钱。
但 Claude Code 一出来,画风就变了。
**Anthropic 自己下场做编程产品,等于直接杀进了 Cursor 的腹地。**原本的“上游供应商”瞬间变成了“正面对手”,再继续把身家性命押在对方的 API 上,显然不是个安全的选择。
所以 Cursor 走上自研这条路,与其说是想成为下一个 Anthropic,不如说是被推着不得不走——
模型握在自己手里,命才在自己手里。
说到这里我很好奇一个问题:在自研模型成功之前,Cursor 现在的模式难道真的不具有护城河吗?
至少对我这种非专业开发者而言,听起来好像 Cursor 还不错——有多款前沿模型可选,价格还更便宜。
带着好奇,我看到 X 上有人给出了一种解读,挺有意思:
Cursor 的护城河从来都不是基础模型,而是 RL 训练流程 + 开发者工作流数据。现在他们正在证明:只要经过足够的微调,开源基础模型在特定任务上也能与前沿模型相媲美。
仔细想想这话也不算太夸张。
Composer 2.5 的训练里,85% 的算力都花在了 Kimi 基模之外的后训练和 RL 上——Kimi K2.5 只是个起点,真正让它在编程任务上能打的,是 Cursor 自己那套围绕真实 IDE 场景做出来的训练管线。
这个打法也解释了为啥它能把价格压到 Opus 的十分之一。因为开源基模省掉了从零预训练那笔最贵的钱,剩下的全砸在编程这一件事上做精细化训练。
模型只为 Cursor 的 IDE 场景服务,没必要为通用能力买单。
至于为啥这次牵手的是马斯克的 SpaceXAI(毕竟老马上次表现得并不友好),逻辑貌似也不复杂。
OpenAI 有 Codex、Anthropic 有 Claude Code、Google 有 Gemini Code Assist,这几家自己都在做编程产品,跟 Cursor 都是潜在对手,算力上指望不上。
剩下能拿出世界级算力集群、又不跟 Cursor 在编程赛道正面冲突的玩家,掰着指头数也没几个了——
老马的 Colossus 2 刚好是现成的。

而且如果把时间线拉长看,你会发现马斯克和 Cursor 之间,已经远不只是单纯的“算力合作”。
今年 3 月,xAI 内部动荡之际,马斯克先从 Cursor 挖走了两位核心工程负责人。
紧接着 4 月,更大的动作来了。SpaceX 宣布与 Cursor 达成合作,由 Colossus 超算为 Cursor 训练模型。
但真正关键的不是算力,而是协议本身。
按照网上披露的条款,SpaceX 获得了未来以 600 亿美元收购 Cursor 的优先权。即便最终不收购,Cursor 也需要支付 100 亿美元“合作费”。
耐人寻味的是,据 TechCrunch 披露,这份协议官宣前几小时,Cursor 原本正要敲定一轮 20 亿美元、估值 500 亿的融资,参投方包括 a16z、英伟达、Thrive 等一线机构。
结果老马一脚插进来,把这单给截胡了。
所以某种程度上而言,这其实是一次非常典型的“马斯克式绑定”:
要么卖给我,要么给我 100 亿,不管怎样先提前把 Cursor 的命运锁进了自己的版图。
至于他前脚煽风点火、后脚卖力站台的变脸速度嘛——硅谷的故事,向来如此。