SF Express と China Post の倉庫で働くロボットが、ついでのように embodied AI の大学入試で1位をさらった
 Tian, Yanlin 2026-05-21 12:40:28 Source: QbitAI
Tian, Yanlin 2026-05-21 12:40:28 Source: QbitAI
RoboChallenge の新しい首位が入れ替わり、清華大系チームが優勝をさらった。
Reported by Tian Yanlin from Ao Fei Temple
QbitAI | WeChat public account QbitAI
embodied intelligence 業界では、はっきりとした変化が起きています。
世界中のロボット企業が、本格的に実機上での競争に乗り出し始めました。
数日前には、Figure が 7×24 時間のライブ配信で物流仕分けを実施し、
Physical Intelligence も、ロボットにさまざまな家事をやらせる試みを続けています。Tesla の Optimus も、Musk から何度も「役に立つ仕事」をするよう求められてきました。
業界全体が、ひとつのことをますますはっきり理解しつつあります。
ロボットの時代における競争は、もはや「どのデモがより派手か」「どのロボットがよりよく動くか」ではありません。

物理世界に深く入り込み、本当に実務をこなせるのは誰か、という勝負です。
結局のところ、ロボットが現実の環境に入ると、問題の性質はまったく変わります。
テーブルには光が反射し、床は汚れて散らかり、物体は遮蔽され、動作には誤差が蓄積していきます。
テーブルを拭く、荷物をつかむ、物を置くといった一見 سادهな作業は、実は認識・計画・制御・記憶を総合的に試す課題なのです。
誰もが「働き者」を名乗ります。では、実際に一番仕事ができるのは誰なのか。
公平に見るなら、やはり各モデルを現実世界に置いて、真っ向勝負で確かめる必要があります。
最新情報として、世界最大級の embodied AI 実機評価プラットフォームである RoboChallenge Table30 が、ランキングを再び更新しました。
結果は業界地図を一気に明快にし、能力差がひと目でわかるものとなりました。
首位に立ったのは、清華大系の新星 embodied robotics 企業・星動紀元(Xingdong Jiyuan)の自社 embodied モデル Era0。世界1位を獲得し、成功率 64.33%、総合スコア 76.34 を記録しました。
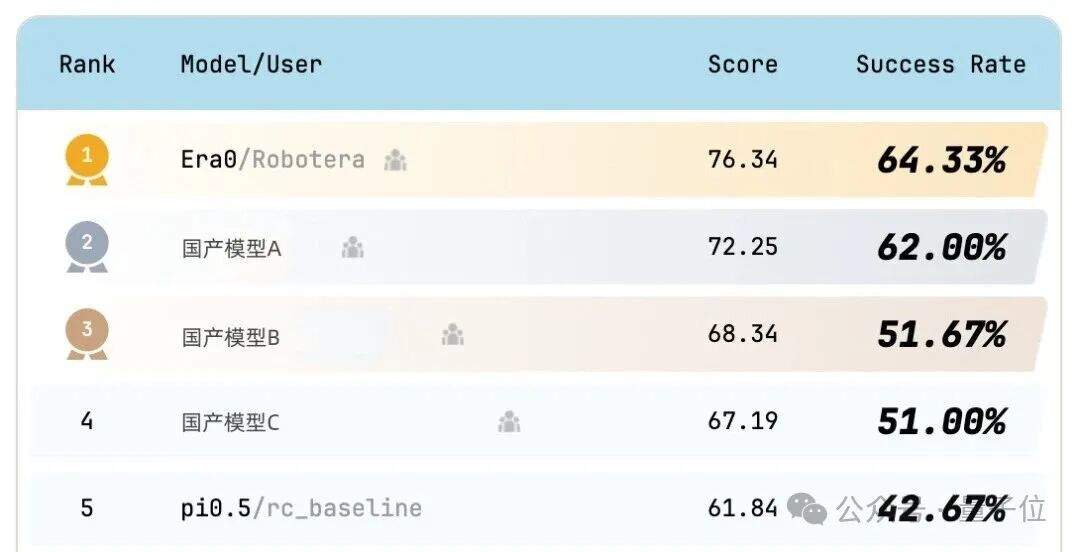
少しヴェルサイユ風に言えば、単一指標だけを攻略して1位を取ったわけではありません。全30タスクのうち、星動紀元 Era0 は 17 タスクで SOTA を達成し、ランキングの新記録を打ち立てました。
見た目はバラバラに見えるこれらのタスクも、突き詰めれば試しているのはひとつのことです。
物理世界で「働き続ける」embodied brain の能力です。
embodied AI の「最難関」ランキングで首位に立つ
RoboChallenge は業界で、しばしば「実機版の入試」と見なされています。
ICRA 2026 Competition に組み込まれただけでなく、CVPR 2026 Workshop Competition(GigaBrain Challenge Track)にも採用され、世界トップクラスのロボティクス・コンピュータビジョン国際会議から正式に認められています。
RoboChallenge で首位を取るということは、モデルが実世界の試験会場を突破したことを意味します。
これは embodied AI プレイヤーにとって非常に魅力的です。
Physical Intelligence の π0/π0.5、Microsoft の CogACT、OpenVLA など、主要な VLA モデルはこれまでもこのランキングで激しく競い合ってきました。
今回も競争は熾烈でした。その激しさは、次の数値だけでも十分に伝わります。
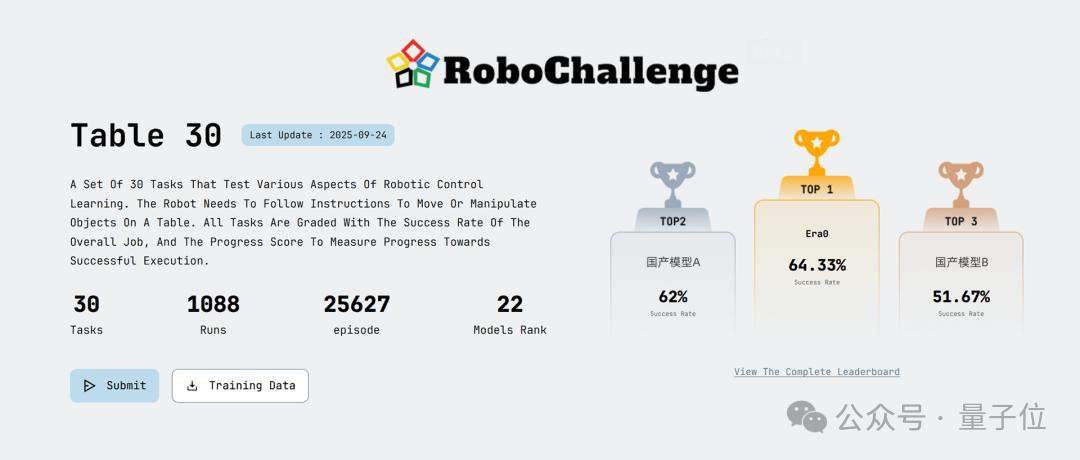
参加した「選手」は 22。30タスクの実行総回数は 1088 回、総エピソード数は 25627 に達しました。
これはデモ動画を数本回すような話ではありません。実機で、何度も何度も本当にテストするのです。
その中でも、業界が特に注目したタスクが2つありました。
- vegan sandwich を作る
- テーブルを拭く
なぜなら……とにかく難しいからです!

まずは sandwich のタスクから見てみましょう。

一見すると、ちょっとしたキッチンゲームのようです。ですが実際には、長期的なタスク計画のテストです。
ロボットは、何を先に取り、何を後で置くかを知っているだけでは足りません。どこまで進んだかも覚えていなければなりません。
パンを置く順番を間違えたり、具材を取り逃したり、ループにハマったりすれば、そのタスクは失敗です。
本質的には、これはロボットが物をつかめるかを見るのではなく、人間のように全体の作業手順を理解できるかを試しています。
次に、テーブル拭きです。

全体の流れは単純そうに見えますが、登場するのはすべて白。白いテーブルを白い紙で拭き、使い終わった紙を白いゴミ箱に捨てます。
ここには、視覚認識、長期タスク計画、接触制御、そして環境状態の記憶が同時に求められます。
特に実世界では、テーブルの汚れは標準化された正解ターゲットではありません。
小さくてばらばらに散らばっていたり、位置が変わったり、反射・影・遮蔽のせいで、ロボットが「もうきれいだ」と誤認してしまうことさえあります。
長い間、この2種類のタスクはほとんど embodied model の能力上限 の代名詞でした。
そして星動紀元 Era0 は、こうした広く知られた難問をまとめて突破したのです。

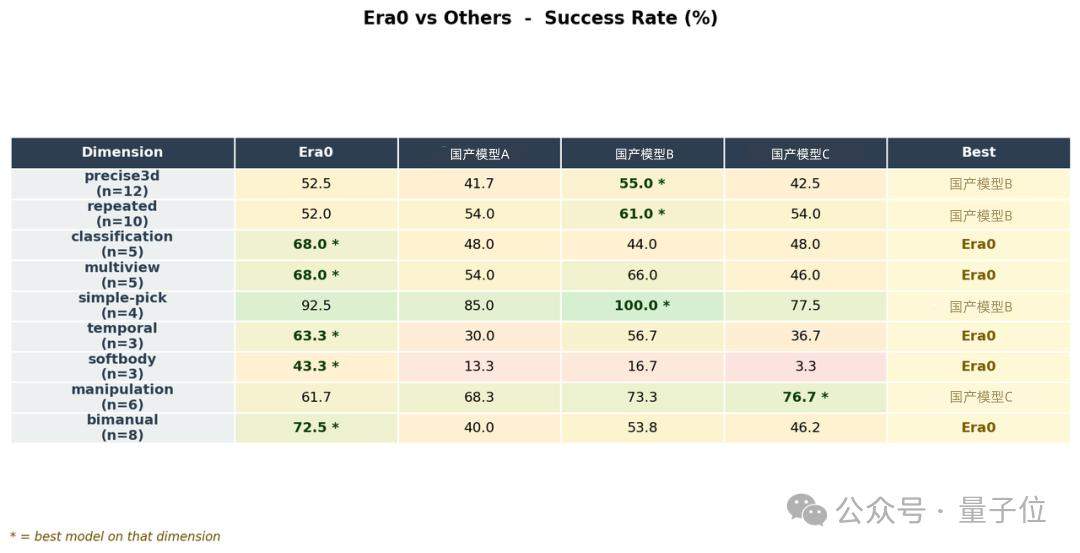
vegan sandwich では、Era0 の成功率は 20% でしたが、Top 8 モデルの中でこのタスクに 非ゼロ のスコアを出せたのは Era0 だけでした。

テーブル拭きでは成功率 60% を達成し、やはり Top 8 の中で非ゼロ結果を出したのは Era0 だけでした。
さらに Era0 は、次の2タスクでプロセススコアも含めて完全な 100 点満点を取りました。
- opener を drawer に入れる
- faucet を開ける

これは Era0 が、たまにひらめく一発屋ではなく、さまざまなタスク・物体・インタラクション環境で安定して動けることを意味します。
ランキング上の30タスクを見渡すと、カバーしている次元は非常に広いことがわかります。
両腕協調、柔軟な物体操作、マルチビュー認識、分類タスク、長期タスク といった複数のコアな器用作業の次元で、Era0 はすべてで1位を獲得しました。
なぜ Era0 は勝てたのか?
Era0 の圧倒的な強さの裏で、業界が本当に注目すべきなのはスコアそのものではありません。
それは、星動紀元が賭けている 非常に野心的な 技術路線です。
同社は従来の VLA 路線をそのまま進めたわけでも、単純に World Model を上乗せしたわけでもありません。
その代わりに、この2つを深く融合 させました。
実際、これを本当にやり切れているチームは業界でもごく少数です。
理由は単純です。この2年間で、VLA は確かに一時期、embodied AI の主流になりました。
視覚・言語・行動のモデリングを統合すれば、大規模モデルのようにロボットが世界を理解できるはずだと期待されたのです。ところが、問題はすぐにどんどん明らかになっていきました。
第一に、長期計画が弱いこと。
多くのロボットは「次の一手」しかできません。しかし現実のタスクは単発の選択問題ではなく、連続した物語のようなものです。
ロボットは次に何をすべきかだけでなく、今プロセスのどこにいて、次に何が起こるのかまで把握しなければなりません。
第二に、幻覚です。
モデルは「もう完了した」と思ってしまうかもしれません。しかし現実の物理世界では、実際には物体は持ち上がっていないし、汚れも拭き取れていません。
そして何より、まだ 連続的な状態理解 が足りません。
 △AI-generated
△AI-generated
ロボットに物理世界で「働き続け」させたいなら、その頭脳には少なくとも3層の能力が必要です。
第1層:正確に見て、安定して位置特定する。
現実世界には ground truth の正解ラベルはありません。暗い照明、重なり、反射は日常の一部です。
多くのモデルは把持が下手なのではなく、そもそも最初にちゃんと見えていないのです。
必要なのは、「一目で全部わかる」という幻覚ではなく、毎回きちんと見分け、正確に位置特定できる信頼性の高い実行者です。
第2層:はっきり考え、プロセスを前に進める。
つまり、時系列記憶 + 長期計画です。
順序が明確な多段階タスク において、迷ったりループしたりせず、手順通りに完了できることが求められます。
第3層:安定して制御し、実際に動かす。
これには、実機上で安定して動作すること、強い汎化と転移、そして速い学習と反復が必要です。
なお、ユーザーが求めているのは、ひと振りで勝つ名人ではなく、堅実に動き、多少のミスはあっても安定して大量処理できる、頼れるエンジニア型かもしれません。
 △AI-generated
△AI-generated
そしてこれを実現するには、模倣学習だけで成功する VLA では不十分です。
問題は、「何をすべきか」はわかっても、「なぜそうするのか」がわからないことです。
たとえば従来の VLA は、物理的な因果理解に欠けています。デモされた行動列を再現することはできても、その動作の背後にある物理的論理、空間関係、相互作用の原理を理解しておらず、なぜそのやり方で操作すべきなのかがわかりません。
環境、物の姿勢、作業位置が少し変わっただけで、元の動作は即座に無効になり、柔軟に適応できなくなります。
同時に、行動の因果関係も理解できず、操作上のリスクを予測したり結果を推論したり、新しい場面へ独力で一般化したりもできません。ただ事前に決めたパターンに従い続けるだけです。
純粋な模倣学習には自然な上限があり、柔軟な操作と自律的な改善が求められる大規模展開の現実的ニーズには到底応えられません。
そこで必要になるのが World Model です。
本質的には、ロボットが未来をあらかじめ 頭の中でシミュレーション し、次の一手を早めに計画できるようにするものだからです。
業界初の、World Model をネイティブに組み込んだロボット基盤モデル PAD から、世界初の embodied world model policy framework VPP まで、星動紀元は World Model を単なる付け足しとして扱ったことはありません。
動画は、言語よりも物理世界を理解するための、より原始的な手段である。
同社は、これをあらゆる技術路線における第一原理だと考えています。
転機は 2025 年 1 月でした。星動紀元が、VLA と World Model を初めて本格的に深く統合したのです。
UP-VLA の発表では、言語推論と視覚予測のどちらも意思決定に役立つことが初めて提案されました。
つまり、ロボットに「頭の中でシミュレーションしながら働く」能力を与えたのです。

しかし World Model はすぐに、業界共通の別の問題に直面しました。実機データが高すぎるのです。
そこで星動紀元は次の研究段階へ進み、World Model 自体にデータを生成させる方向へ舵を切りました。
2025 年 10 月、スタンフォード大学の Chelsea Finn チームと共同で、「制御可能な生成型 World Model」Ctrl-World を発表しました。

業界で初めて、World Model は データシミュレーター になりました。
ロボットはもはや t