AI時代は「現場」を押さえた者のもの:モビリティ領域で注目すべきデータプレイヤーが台頭
フルシナリオのデータとエンドツーエンドのサービスが、AI大規模モデルの効率的な反復を後押ししている
Jessica、Aofei Templeより
QbitAI | WeChat公式アカウント QbitAI
AI業界で最も希少な“ホット商品”は、変わりつつある。
フェイ・フェイ・リーが**「空間知能」を提唱して以降、業界全体ではより明確な潮流が見え始めている。大規模モデルに続き、世界モデルと身体性知能**が、資本と産業の新たな焦点になりつつあるのだ。
しかし、AIが現実の物理世界を理解し、そこに作用する方向へ移り始めるにつれ、ある厄介な現実も浮かび上がってきた。
こうしたモデルの学習に必要な現実世界の相互作用データは極端に不足している。需要と供給の差は、業界関係者の中にはほぼ10万倍に達する可能性があると見る人もいるほどだ。
従来、大規模モデルは膨大なテキストや画像から言語理解・生成を学習できた。しかし身体性知能には、**「判断 → 行動 → フィードバック」**という完全な連鎖が必要であり、因果性や相互作用を欠く静的データでは、もはや要求を満たせない。
業界が今まさに必要としているのは、因果ロジックを持ち、継続的に生成できる、現実世界の相互作用データという新しいタイプのデータだ。

その結果、高品質な物理世界データは戦略的に希少な資源となった。しかも、それを低コストかつ大規模に継続生成できるプレイヤーが、ますます脚光を浴びている。
興味深いことに、QbitAIが業界関係者に取材したところ、AI時代の大きな物理世界データの入り口の一つは、多くの人が想像もしない業界から現れつつあるという。すなわち、モビリティプラットフォームだ。
気づいていないかもしれないが、日常的に使っているモビリティサービスのプラットフォームは、配車や移動サービスを提供しているだけではない。新たなデータ事業によって、裏で収益を積み上げているのだ。
モビリティプラットフォームは、データで「副収入」を稼ぐ時代に入ったのか?
モビリティサービス業界では、静かに勢いを増している新しいビジネスモデルがある。膨大な一次取得の実走行データを持つプラットフォームが、データ資産化とデータサービスを通じて、第2の成長曲線を切り開こうとしているのだ。
そしてこの分野では、すでにデータの収益化に成功し、商用化の道筋を最初に実証したプレイヤーもいる。
その具体的な数字を最初に公表したのが、GAC Group傘下のモビリティサービスプラットフォームであるRuqi Mobilityだ。

Ruqi Mobilityは2025年の財務報告で、主な収益源がAIデータ事業である技術サービス部門が、同社で最も高い成長率を示す部門になったと開示した。
このAIデータ事業とは、Ruqi Mobilityのデータ事業部門(以下、「Ruqi Data」)を指し、2023年に設立された。
当時、Ruqi Mobilityは2023年5月に測量・地図作成のB級資格を取得し、LiDAR、高精度慣性航法システム、周囲カメラなどのセンサーを搭載したインテリジェント運転データ収集車両を本格運用し始めた。
これらの車両はモビリティサービスを提供する一方で、実際の走行・道路データを適法に収集していた。データ収集の過程で、Ruqi Dataはデータサービス能力を継続的に拡張していった。

さらに最近では、Ruqi Dataが保有するAIデータ資産と能力の全体像を初めて公開した。
公開情報によれば、同社のデータ資産は現在、アノテーションデータ、行動データ、合成データ、マルチモーダル学習データセットの4大カテゴリをカバーしており、一次取得から処理、納品までの全工程を網羅している。
このうち、アノテーションデータは基盤を成し、行動データは実走行環境におけるドライバーの運転判断を記録する。合成データはロングテールなシナリオを補完するために用いられ、マルチモーダル学習データセットは画像・テキスト・音声・動画をカバーし、大規模モデルの垂直分野向けファインチューニングにそのまま使える。
規模の面でも、Ruqi Dataはかなり広範なデータ収集ネットワークを構築している。
2026年5月時点で、同社は広州、上海、重慶、瀋陽などの都市に、300台超のインテリジェント運転データ収集車両を配備していた。
約3年にわたる定常運用を通じ、これらの車両は1日あたり1,600時間分、130TBのデータを生み出している。さらにプラットフォームには、数千万件規模の高価値な走行シナリオクリップも蓄積されている。
これらのクリップの背後には、完全な現実世界での相互作用プロセスがある。こうして見ると、プラットフォームが生み出すデータは、まるで継続的に生成される物理世界の“断面”のようだ。
そして、規模だけでなく、商用化の進展こそが、このモデルが機能するかどうかを左右する本当の試金石だ。
Ruqiの財務報告によれば、2025年における主な収益源がAIデータサービスである技術サービス部門の売上高は、1億6,000万元で、前年同期比487.4%増となった。
この成長率は、高品質な物理世界データに対する需要が急速に顕在化していることを示している。
Ruqi Dataの顧客構成も、これを裏付けている。同社によると、サービス領域はインテリジェント運転、身体性知能、大規模モデル、コンシューマーエレクトロニクス、医療など多岐にわたり、Tencent、Pony.ai、Li Auto、Volcano Engine、Baidu AI Cloud、GAC Groupといった大手企業が顧客に含まれる。

つまり、モビリティ事業から生まれたデータサービスは、すでに業界横断で実問題を解決できる力を持ち、データ収集・処理から商用納品までの完全なクローズドループを実現している。
その結果、Ruqiのようなモビリティプラットフォームに対する見方も更新された。
フルチェーンのデータサービス能力を備えたRuqiは、もはや単なる配車サービス事業者でも、従来型のデータアノテーション企業でもない。**「データセット+フルスタック能力」**を軸にした総合サービス提供者へと進化しつつあるのだ。
そして、この**「データセット+フルスタック能力」**というクローズドループ能力は、次世代AIに不可欠な基盤インフラの一つになる可能性が高い。
なぜモビリティプラットフォームが突然AIインフラになったのか?
モビリティプラットフォームの変化をより深く理解するには、さらに根本的な2つの問いに分解するとわかりやすい。
なぜAI業界は、これほどまでに物理世界データを渇望しているのか?
そして、なぜモビリティプラットフォームは、そのギャップを埋めるのに最適なのか?
出発点は、フェイ・フェイ・リーによる世界モデルの定義にある。彼女は、現在主流の大規模言語モデルには致命的な欠点があると考えている。それは、「空間知能」、すなわち三次元の物理世界を知覚し、推論し、その中で行動する能力を欠いていることだ。
そのためフェイ・フェイ・リーは、人間のように3D物理世界の動作原理を理解し、そこに働きかけられる新しいAIシステムの構築を提唱している。
このシステムこそが、彼女の言う**「世界モデル」**だ。世界モデルには、生成性、マルチモダリティ、相互作用性という3つの核心要件がある。

つまり、次世代AIの学習データはこの3つを同時に備えていなければならない。とりわけ重要なのが相互作用性で、単なる受動的な視覚コンテンツでは足りず、行動→フィードバックの因果連鎖全体を含む必要がある。
問題は、現在業界が安定的に取得できる物理世界の相互作用データが、学習ニーズに対して到底十分ではないことだ。
その理由は、従来のデータ供給が主に次の3つで、それぞれに限界があるからである。
- まず、インターネット上の公開画像や動画をクロールする方法。これは静的なものが中心で、相互作用情報に乏しい。
- 次に、研究室やシミュレーション環境でシーンを手作業で構築する方法。これはコストが高く、スケールさせにくい。
- そして、クラウドソーシングによる収集。これはデータ品質や一貫性の担保が難しい場合がある。
短期的には、これら3つの方法のいずれも、因果ロジックを備えた相互作用データを継続的かつ大規模に生み出すことはできない。
これこそが、現在の業界が直面する中核ボトルネックだ。相互作用ラベルを持つ、高品質かつ高忠実度な物理世界データは極めて希少であり、供給と需要の間には大きなギャップがある。
こうした背景のもと、モビリティ領域は、まさにこの種の高価値データを生成・蓄積するために必要な自然な優位性を備えている。
従来のデータ供給手法とは異なり、モビリティプラットフォームは実運用の中でデータを取得する。
各データ収集車両は、いわば移動型のセンシング端末であり、日常のモビリティサービスをこなしながら、ドライバーの判断 → 車両の応答 → 環境からのフィードバックという完全な相互作用の連鎖を記録している。
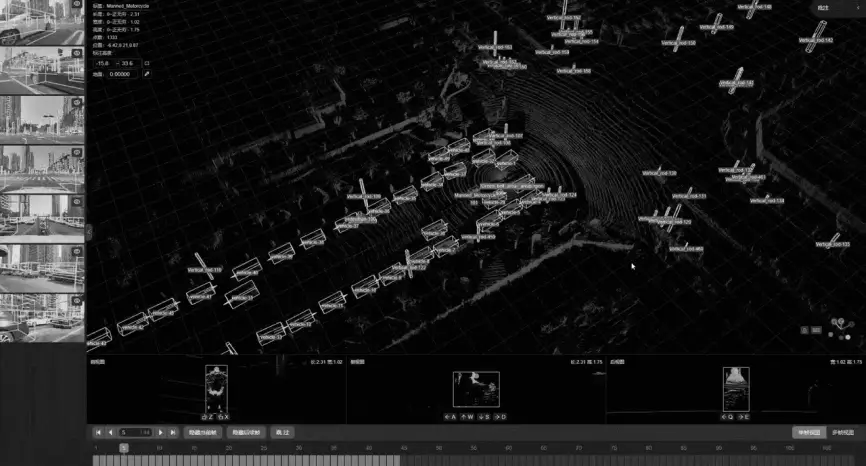
このクローズドループなデータは、自然にマルチモーダルな整合性、時間的連続性、因果ロジックを備えている。
Ruqiが公開している駐車シナリオを例に挙げよう。
Ruqi Dataは、3D障害物の位置を記録するだけでなく、車両シャシーのCAN信号(ハンドル角度やアクセル/ブレーキ入力などの車両状態を反映)、ミリ波レーダーのエコー、LiDARの点群、カメラ映像も収集している。
駐車シナリオを中心に、これらのマルチモーダルデータは**「行動(ドライバー操作) - 状態(車両応答) - 環境(周囲のフィードバック)」**という統合データセットを形成する。
AIの学習において、この種のデータはモデルに何が起きているかを伝えるだけでなく、なぜそうなるのかまで理解させる助けになる。たとえば、なぜ譲るべきなのか、駐車スペースが空いているかどうかをどう判断するのか、といった、常識的な物理感覚と因果推論を要するタスクだ。
AI大規模モデルの学習を長く追ってきたあるアナリストはQbitAIに対し、推論・判断・フィードバックの完全な連鎖を持つデータこそが、空間知能モデルを学習させるための「金脈」だと語った。
まさにこの独自のデータソースを土台にして、Ruqi Dataはフルチェーンのサービス能力を体系的に構築してきたのだ。
技術面では、Ruqi Data独自のOCC自動アノテーションアルゴリズムが、ソースと整合したベースマップと自動アルゴリズムを活用し、手作業のアノテーション時間を90%削減しつつ、納品精度98%以上を実現している。
また、合成データモジュールでは、雨、霧、雪、夜間といったロングテールシナリオをワンクリックで生成でき、実世界収集の不足を補える。さらに、マルチモーダルデータセットは画像・テキスト・音声・動画をカバーし、大規模モデルの垂直分野向けファインチューニングを直接支援できる。

この能力の本質は、自動運転分野で実証されたデータエンジニアリングの経験――適法な収集、大規模なクレンジング、精密なアノテーション、合成拡張――を、標準化された製品としてパッケージ化することにある。
顧客は「そのまま使える」形で、基盤となる収集・処理能力を一から構築することなく、深く加工された標準化データセットとツールチェーンを直接利用できる。
この点で、Ruqi DataはロジックとしてScale AIにやや近い。
単にデータを提供するだけでなく、顧客が「データをよりよく理解し、より効率的に活用する」ためのツールと方法論も提供することで、高品質な物理データの利用障壁を下げ、モデル反復の効率を高めている。