Taichu Yuanqi Hongyuan: 異種計算は将来のAIコンピュートインフラの重要な方向性になる | AIGC2026
AI業界は、再び高強度の計算サイクルに入っている
AIGC2026編集部による編集
QbitAI | WeChat公式アカウント QbitAI
2026年、AI業界は再び高強度の計算サイクルに入っています。
Agentic AI、コーディングアシスタント、インテリジェントオフィスツールといったアプリケーションが実運用へと加速するなか、AIはデモから実務へと移行しつつあり、トークンはAI時代におけるリソース消費の中核単位になっています。
その結果、計算基盤がより高頻度で複雑なAIアプリケーションを支えられるかどうかが、業界が次の段階でも前進できるかを左右する重要な問いになっています。Taichu YuanqiのCPO兼SVPであるHong Yuanは、次のように述べています。
トークン経済の加速を背景に、AIコンピュートはフレームワーク、モデル、アプリケーションをよりよく支え、大規模モデルの学習、推論、業界導入に向けて、より安定的で高効率、かつ使いやすい基盤レイヤーを提供する必要があります。
大規模モデルの能力が飛躍的に向上し、AIアプリケーションが急速に成長するなかで、トークン利用需要は引き続き解放されており、国産コンピュートにも新たな発展機会が訪れています。
これは、計算基盤がもはやモデル学習の背後にある単なる基礎資源ではなくなることを意味します。むしろ、モデル開発からアプリケーション展開、業界シナリオまでの全チェーンを貫く存在となり、トークン知能時代における最も重要な新インフラになるということです。
今年の QbitAI AIGC2026 では、Hong Yuanが国産AIコンピュートの発展について、国産コンピュート、トークンアプリケーション、Agentic AIの計算効率といったキーワードを軸に見解を共有しました。

Hong Yuanの考えをできるだけ正確に伝えるため、QbitAIは原意を変えずに講演内容を編集・整理しました。皆さまの参考になれば幸いです。
AIGC2026はQbitAIが主催する業界サミットで、約20名の業界代表が討論に参加しました。会場には1000人以上が来場し、オンライン配信の視聴者は400万人近くに達し、主要メディアからも大きな注目と報道を集めました。
要点
- Agentic AI、業界特化型大規模モデル、インテリジェントアプリケーションが実際のビジネスシーンに入るにつれ、AIコンピュートは「コンテンツを生成する」段階から「タスクを生成する」段階へと移行しており、計算基盤の安定性、効率、協調性にこれまで以上の要求が生じている。今後解くべき課題は、異なる計算ユニットをどう連携させるか、どう協調的にスケジューリングするか、待ち時間や通信コストをどう削減するかである。
- 国産AIコンピュートには新たな発展機会があるが、真の突破口はピーク性能だけではなく、大規模クラスタのサービス能力、計算効率、エコシステムの使いやすさにある。
- 大規模モデルの学習と推論は、数万枚規模、さらにはそれ以上のクラスタへと向かっている。コンピュートベンダーは、ハードウェア、相互接続、ソフトウェア、スケジューリング、運用を含む全チェーンでシステム能力を高める必要がある。
- エージェントのタスク実行では、CPUのスケジューリング、GPU計算、通信、データ処理が高効率で連携する必要がある。異種計算は将来のAIコンピュートインフラにおける重要な方向性となる。
- 将来のAIコンピュートは、トークン経済における「酸素発生装置」のように、モデル、アプリケーション、業界シナリオの稼働を絶えず支え続ける。
以下はHong Yuanによる講演全文です。
トークン経済の加速とともに、国産AIコンピュートに新たな機会が訪れている
2022年末にChatGPTが公開されて以来、大規模モデル業界全体のイテレーション速度は明らかに加速しており、特に今年に入ってからは、主要な大規模モデルの更新頻度がさらに高まっています。
計算基盤ベンダーにとって、これは主流の大規模モデルに継続的に適応し、最適化していく必要があることを意味します。
モデル数、学習データ規模、必要な計算規模、そしてモデル自体のパラメータ規模に至るまで、非常に明確な成長トレンドが見て取れます。
こうした背景のもと、今年は業界でトークン経済について語られる機会もますます増えました。大規模言語モデルの利用が急速に伸びるなかで、トークンはAI時代における最も重要な消費単位の一つとなっており、国産モデルに関連する利用需要も引き続き増加しています。
OpenRouterのデータに基づく予測によると、総トークン使用量は2025年から2026年、さらに2030年にかけて大幅に増加すると見込まれています。
その伸びは212倍に達します。今後は、コンシューマー向けアプリでも、企業・業界向けアプリでも、トークン消費がはるかに大きな規模で拡大していくことが予想されます。
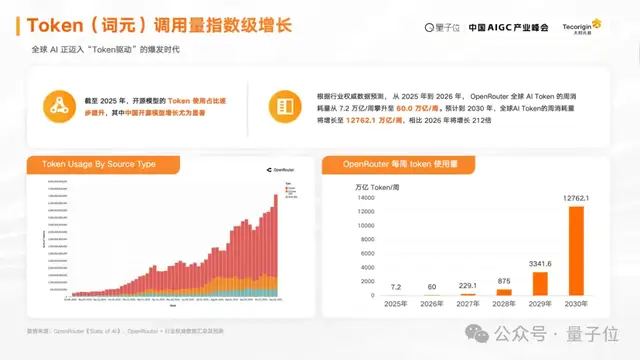
トークン利用の急成長に伴い、AIアプリケーション市場も急速に拡大しています。ますます多くのアプリケーションが実シーンへと入り、オフィス、生産性向上、コーディング、医療、教育、エネルギー、電力といった分野でもAI機能の導入が加速しています。
これは同時に、基盤となるコンピュートインフラが、より高頻度で、より複雑かつ大規模なAI需要を支えなければならないことを意味します。
このプロセスでは、計算効率の向上がさらなる需要を呼び起こします。生産性が上がれば、より多くのアプリケーションシナリオが生まれ、利用頻度も増え、最終的には計算需要の継続的な増加につながります。
IDCおよび国内の一部研究機関のデータによると、2030年までに世界の計算規模は年率60%で成長し、そのうち90%以上がインテリジェントコンピュートになると予測されています。
国産AIコンピュートにとって、これは非常に重要な発展機会です。大規模モデルの能力がさらに向上し、トークン需要が急速に解放され、業界アプリケーションが実導入へと加速するなかで、国産コンピュートはより広範な業界シーンへと押し出されています。
大規模モデルがタスク時代に入ると、AIコンピュートは3つの重要課題を解く必要がある
もちろん、新しい機会には新しい課題が伴います。国産AIコンピュートについて言えば、主に解決すべき重要な問題が3つあると考えています。
1つ目は、大規模クラスタのサービス能力です。
今日、大規模モデルの学習と推論はクラスタ規模に対してますます高い要求を突きつけています。多くの場合、数万枚規模、あるいはそれ以上のクラスタが必要です。このような大規模システムでは、学習効率、システムの安定性、コスト制御、信頼性をどう確保するかが、計算基盤企業にとって解決すべき課題です。

2つ目は、計算効率です。
エージェントのタスク実行では、ユーザーがタスクを投入した後、システムはタスク計画、ツール呼び出し、多段階実行、結果フィードバックを行う必要があります。この過程で、GPUが実際に計算に使われる時間は全体の約10%に過ぎず、多くの時間はCPUのスケジューリング、通信、データ処理などに費やされます。
CPUは主にシリアル計算とスケジューリングを担当し、GPUは並列計算に強みがあります。今後のAIコンピュートシステムは、CPUやGPUなど異なる計算ユニットの協調効率をより高める必要があり、タスク実行の全体チェーンをより効率的にする必要があります。
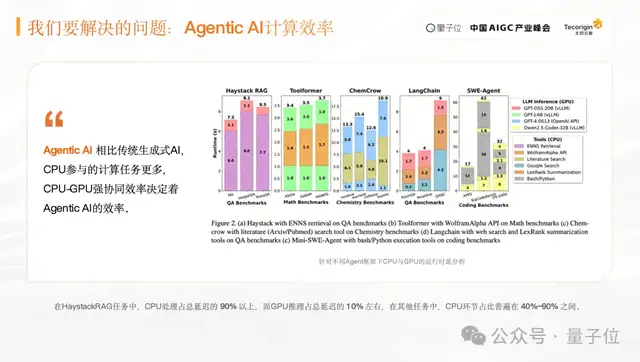
3つ目は、エコシステムです。
国産コンピュート企業にとって、チップ設計そのものは第一歩にすぎません。本当にユーザーが採用し、開発者が使いたくなり、モデルやアプリケーションを迅速に移行できるかどうかを決めるのは、その背後にあるソフトウェアエコシステムです。
トークン経済にしっかり応えるためには、国産コンピュートは開発者や業界顧客に、より使いやすく便利なエコシステム機能を提供しなければなりません。低レイヤーの開発者であれ、上流のモデルベンダーやアプリケーションベンダーであれ、モデルの移行、学習、ファインチューニング、推論展開をよりスムーズに行える必要があります。
AIコンピュートの発展は、もはや単純に性能や計算力を積み上げるだけでは成り立ちません。 特にAgentic AIが急速に台頭するなかで、AIコンピュートはコンテンツ生成からタスク生成へと移行しており、計算システムには新たな要求が生じています。今後のAIコンピュートには、異種協調、高効率な使いやすさ、エコシステムの互換性といった体系的な課題への対応が求められます。
AIコンピュートが「コンテンツを生成する」段階から「タスクを生成する」段階へ移るにつれ、異種協調はますます重要になります。今後解くべき課題は、異なる計算ユニットをどう連携させるか、どう協調的にスケジューリングするか、待ち時間や通信コストをどう削減するかです。
スーパーコンピューティングの蓄積からエコシステム適応へ、AI産業の「酸素発生装置」を築く
こうした課題に対して、Taichu Yuanqiも継続的に探索を進め、実践を重ねてきました。
まず、大規模クラスタの面では、高性能計算における長年の技術蓄積があります。特に、10万コア規模、あるいは数十万コア規模に及ぶ大規模並列計算タスクにおける協調計算の経験は、現在構築しているAIコンピュートクラスタにとって重要な基盤となっています。
次に、異種計算の面では、チップ設計レベルでそれに応じた配置を行っています。
当社のコアチップ設計には、汎用計算モジュール、データ処理コア、並列計算モジュールなど、異なる計算モジュールが含まれています。これらの計算ユニットはオンチップネットワークで接続されており、CPUやGPUなど異なる計算ユニット間の協調効率を高めています。
このようなアーキテクチャは、今後のAIタスクがますます複雑化する流れに適応することを主な目的としています。AIアプリケーションはもはや単一モデルの推論にとどまらず、タスク分解、ツール呼び出し、データ処理、複数ラウンドの対話、結果フィードバックを伴うようになります。こうしたタスクチェーンに直面したとき、基盤となるコンピュートシステムには、より強い協調能力が必要です。
さらに、エコシステムの面も非常に重要だと考えています。
基盤レベルでは、自社開発のプログラミングフレームワークとプログラミング言語のサポートを提供しており、成熟した開発エコシステムも取り入れ、開発者がより簡単に始められるようにしています。Pythonに慣れた開発者も、関連ツール群の上に構築できます。
さらに上の層では、自然言語インタラクションに基づく演算子の自動生成も模索しており、開発の敷居を下げることを目指しています。学習、ファインチューニング、推論など各段階にまたがって、より完全な統合ソリューションを提供したいと考えています。
同時に、Taichu Yuanqiは、異なるフレームワーク間でモデルをワンクリック移行できる各種ツールコンポーネントも提供しています。
フレームワークからモデルまで、さまざまなサードパーティ製フレームワークライブラリやモデルライブラリへの適応も進めており、モデルベンダー、アプリケーションベンダー、業界顧客が国産コンピュートをよりスムーズに利用できるよう支援しています。
トークン経済が到来すると、計算基盤はAI業界全体にとって、人間にとっての酸素のように重要になります。私たちが構築している新しいインフラは、絶えず酸素を供給し続けるシステムのようなものです。
Taichu Yuanqiがこれまで常に行ってきたこと、そして今後も続けていくことは、業界パートナーと手を取り合い、それぞれの強みを引き出し、上流・下流のリソースを連携させ、中国のAI産業に安定的で高効率な、