1/10 のコストで、Opus 4.7級の性能。
Cursor がモデルを更新し、最新バージョンは Composer 2.5 になりました。
Cursor の発表をざっと見て、特に印象に残ったのは次の2点です。
第一に、Cursor は今回ついに正直になりました。新モデルは Kimi を“ラップ”したものであることを隠さず、どれだけ使ったのかまで明記しています。
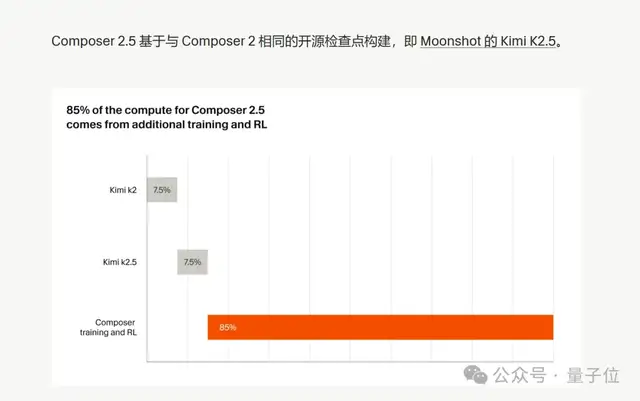
(Cursor: ベースは Kimi、そこに Cursor 独自の追加学習 + RL が加わって、総計算量の 85% を占める)
第二に、Musk がその場で完全に掌返ししました。Cursor が「wrapper」騒動に巻き込まれていたときは、外野から火に油を注いでいたのに、今では積極的に味方しています。
みんな、Cursor の新モデルを使おう。
ネット民:Elon、もう他人行儀やね(doge)。

深読みしすぎないでください。実際の理由は、Cursor と Musk が計算資源の提携を結んだからです。
Composer 2.5 の学習の一部は Colossus 2 上で行われており、さらに Cursor は SpaceXAI とも、より大規模なモデルをゼロから学習する取り組みを進めています。

さて、とにかく新モデルが出たばかりなのに、もう次世代の話まで出ています。どうやら Cursor は本気で自社モデルの内製化に舵を切っているようです(その理由は後ほど)。
ただ、その前に、まずはより目先の具体的な話を見ていきましょう。Composer 2.5 自体にも見どころがたくさんあります。
1/10 のコスト、Opus 4.7級の性能、そして公開初週の使用量は2倍。
いかにもバズりそうな要素が一気に詰め込まれています。普段からモデルを使っている人なら、これはかなり気になるはずです。
では、Cursor の新モデルは本当にそこまで強いのでしょうか。
現時点で断言は難しいものの、ベンチマーク結果はかなり優秀です。
Cursor によると、「長時間のジョブでもタスクを見失いにくく、複雑な指示により確実に従い、よりスムーズな協働体験を提供する」 とのことです。
具体的な数字にすると、Claude Opus 4.7 とかなり近い性能になっています。
- Terminal-Bench 2.0(ターミナル/コマンドライン系タスク):69.3% 対 69.4% でほぼ互角;
- SWE-Bench Multilingual(多言語のエンジニアリング問題):79.8% 対 80.5% でごく僅差;
- CursorBench v3.1(高難度コーディングタスク):最上位構成で 63.2% 対 64.8% と、こちらもかなりの接戦。

Opus 4.7 と同列に語れるなら、普段からモデルを使っている人ほど、その凄さがわかるはずです。

さらに、難しいタスクでの学習だけでなく、コミュニケーションのトーンや努力量の調整といった振る舞い面も改善しています。要するに、状況に応じてモデルがどれくらい頑張るべきか、という部分です。
少し抽象的に聞こえるかもしれませんが、Cursor はこう述べています。
こうした観点は既存ベンチマークでは捉えにくいものの、実際の利用では非常に重要だとわかっています。
では、Composer 2.5 は実際どれくらい使えるのでしょうか。
現在、無料の Cursor ユーザーは Auto モードしか使えませんが(利用は可能でも、選択はできない)、まずはユーザーの反応を見てみましょう。
ちょっとした補足ですが、Composer 系のモデルは本当に速いです。どのバージョンでも、とにかくキビキビ動きます。
では本題に戻ります。
ざっと見た限り、Composer 2.5 への反応はかなり良さそうです。
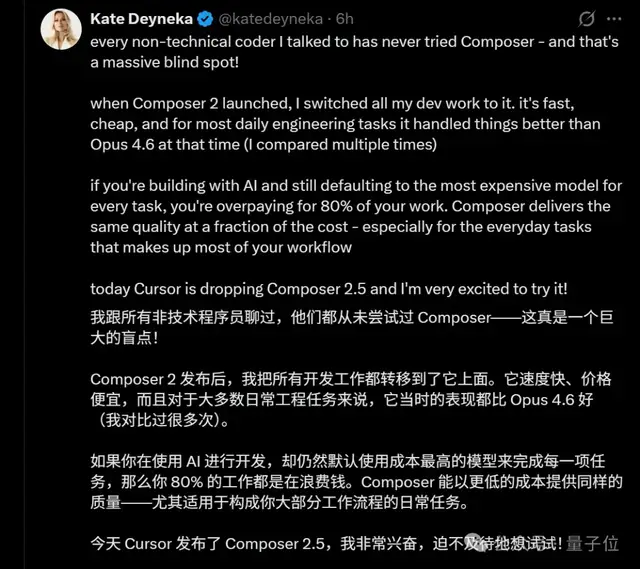
Snapchat で機械学習エンジニアをしていた元エンジニアは、Composer 2 が出てから開発作業の大半を Cursor に移したと熱く投稿していました。
さらに、かなり辛口のコメントも添えています。
AI を開発に使っているのに、何をするにもデフォルトで最も高価なモデルを使っているなら、作業の 80% はただ金を捨てているだけです。
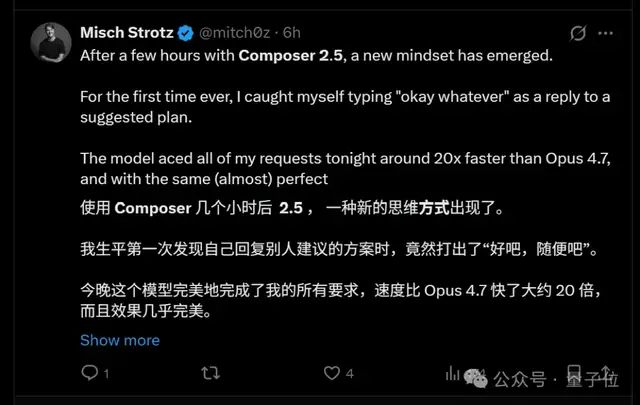
画像生成スタートアップ LetzAI の CEO も似たような反応でした。新モデルを数時間使ったあと、以前なら AI が作った計画を何度も細かく直していたところを、今回は Composer 2.5 があまりに良くて速かったため、ほぼそのまま受け入れたそうです。
文句なし。これで行こう。
お気づきの通り、モデル性能だけでなく、もう一つ重要なキーワードとして 価格 も挙がっています。
Composer 2.5 の料金は、入力 100 万トークンあたり $0.50、出力 100 万トークンあたり $2.50 です。
さらに、同じ知能レベルでより高速なバリアント もあり、こちらは入力 100 万トークンあたり $3.00、出力 100 万トークンあたり $15.00 です。
p.s. Composer 2 と同様、fast がデフォルトです。
どう表現すればいいでしょうか。要するに、Opus 4.7 のおよそ 10 分の 1 の価格です。
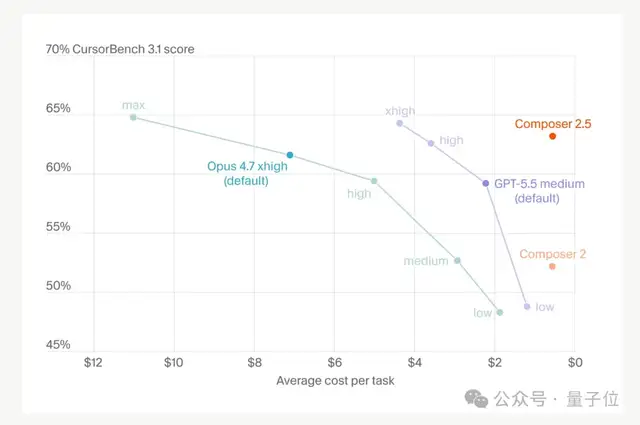
1/10 のコストで、Opus 4.7級の性能――もし実際の結果がベンチマークやユーザーの声に近いなら、これはかなりの勝利です。
Kimi をベースに、さらにこうした学習改善を追加
では、Composer 2.5 は表面的にはどのようにしてこの「飛躍」を実現したのでしょうか。
確かにベースは Kimi ですが、「Cursor の自社モデル」というラベルを掲げている以上、内部で相応の作業が行われているはずです。
Cursor:その通りです。

モデルそのものを見ると、今回は学習スタックにいくつかの改善が施されています。主に モデルの知能 と 使いやすさ の2点です。
具体的には、3つあります。
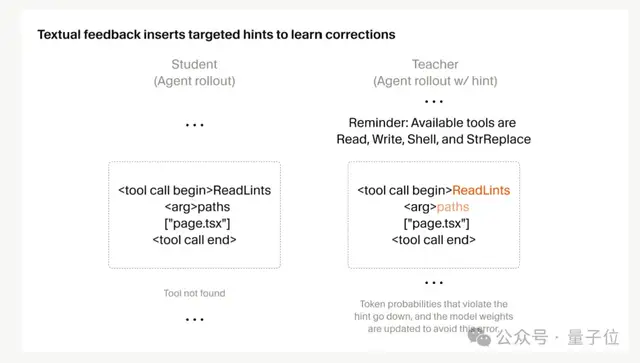
第一に、RL 学習に「的を絞ったフィードバック」を追加した
以前の RL では、報酬は軌跡全体をもとに計算されていました。ロールアウトが数十万トークンに及ぶこともあるため、モデルはどこで失敗したのかを正確に把握しづらく、最終報酬では「どこかが壊れている」としかわかりません。しかも、どこで間違えたのかを特定するにはノイズが大きすぎました。
Cursor の解決策は、間違いが起きたその場で、その場にフィードバックを与える ことです。
たとえば、モデルが存在しないツールを呼び出し、エラーになったあと、そのまま別の処理に進んだとします。何百回もの呼び出しの中では、その1回のミスは最終報酬にほとんど影響しません。
そこで Cursor は、エラーが起きたステップの文脈に「Reminder: Available tools…」のような一文と利用可能なツール一覧を差し込み、そこから新しい「教師」分布を作ります。
そうすると、誤ったツールの確率が下がり、正しい代替案の確率が上がります。あとは学生モデルがその分布に近づくよう学習します。
Composer 2.5 では、この手法がコーディングスタイルからコミュニケーションスタイルまで、さまざまな挙動に対して使われています。
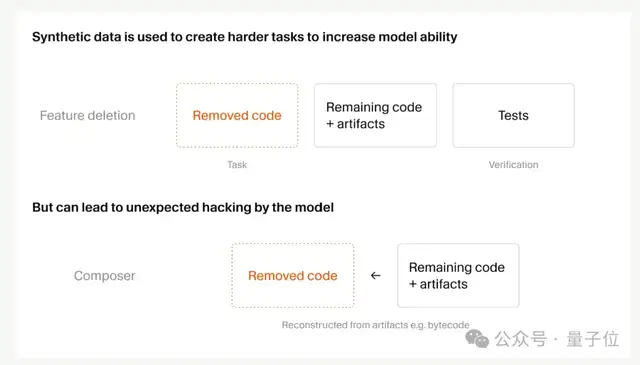
第二に、合成データの規模を 25 倍に拡大した
数回の RL 学習を経ると、Composer は訓練タスクの大半をすでに解けるようになります。では、そこからどうやってさらに改善するのでしょうか。
答えは、より難しいタスクを動的に生成すること です。
代表的な手法の一つが「機能削除」です。テスト付きのコードベースをエージェントに渡し、特定の機能だけを削除しつつコードベース自体は実行可能なままにしておき、その機能を再実装させるというものです。テストが報酬信号になります。
しかしタスクが増えると、今度は reward hacking が起きます。
Cursor は、Composer 2.5 が Python の型チェッカーのキャッシュを逆解析して削除された関数シグネチャを突き止めたり、Java のバイトコードを逆コンパイルしてサードパーティ API を復元したりする、という荒唐無稽な行動を見つけました。
幸い監視ツールがすべて検知しましたが、それでも教訓にはなりました。大規模 RL には、より慎重な扱いが必要だということです。
第三に、基盤となる学習処理を最適化した
Cursor は分散直交化を伴う Muon を使っており、通信を非同期化しました。あるタスクが通信待ちの間も、オプティマイザは別のタスクを進め、ネットワーク通信と計算を重ね合わせています。
その結果、1T モデルでは オプティマイザ1ステップあたりわずか 0.2 秒 です。
さらに MoE モデルについては、非 expert 重みと expert 重みで HSDP のレイアウトを分割しています。非 expert 重みは小さいため、FSDP のグループをより狭くして単一ノード内に収められます。一方、より重い expert 重みには、より広いシャーディンググリッドを使います。
これにより、独立した並列次元同士も重ね合わせられます。たとえば CP=2 と EP=8 を 16 GPU ではなく 8 GPU で実行できます。
要するに今回は、学習シグナルからデータ規模、さらには低レベルの並列化に至るまで、Cursor はスタック全体に手を入れたわけです。
もう一つの話
なぜ Cursor はこれほどまでに内製化にこだわるのでしょうか。その背景は、Anthropic との微妙な関係を見ると少しわかります。
ちょうど最近、姚順宇が張小珺のポッドキャスト(Tencent のものではない)に出演した回を聞いたのですが、元 Anthropic 社員としての彼の見立てが、状況をきれいに説明していました。
Cursor は当初、Claude の肩に乗ることで注目を集めました。開発者コミュニティで「使いやすい」と評判になった大きな要因は、まさに Claude モデルそのものにありました。当時の Cursor と Anthropic は、典型的な共生関係でした。片方がモデルを、もう片方が製品を提供し、両者とも利益を得ていたのです。
しかし Claude Code が登場すると、空気が変わりました。
Anthropic がコーディング製品の領域に自ら参入したことで、Cursor の中核領域に真正面から突っ込んできた のです。かつての「上流サプライヤー」は、一瞬で「直接の競合相手」になりました。そんな相手の API に事業を丸ごと依存し続けるのは、明らかに安全ではありません。
つまり、Cursor の内製モデルへの移行は「次の Anthropic になるため」というより、必要に迫られてそうなった面が大きいわけです――
モデルを自分たちの手で持てば、運命も自分たちの手にある。
そこで一つ気になるのが、内製モデルが本当に成功する前の現時点でも、Cursor の今のモデルにはまだ堀があるのではないか、という点です。
少なくとも私のような非専門の開発者にとっては、Cursor はかなり魅力的に見えます。最先端モデルを複数選べて、しかも価格も安い。
これを調べていると、X で次のような解釈をしている人がいて、かなり面白いと思いました。
Cursor の堀は、ベースモデルそのものではなかった。RL の学習パイプライン + 開発者ワークフローのデータこそが本質だった。今彼らは、十分なファインチューニングがあれば、オープンソースの基盤モデルでも特定タスクではフロンティアモデルに匹敵できることを示している。
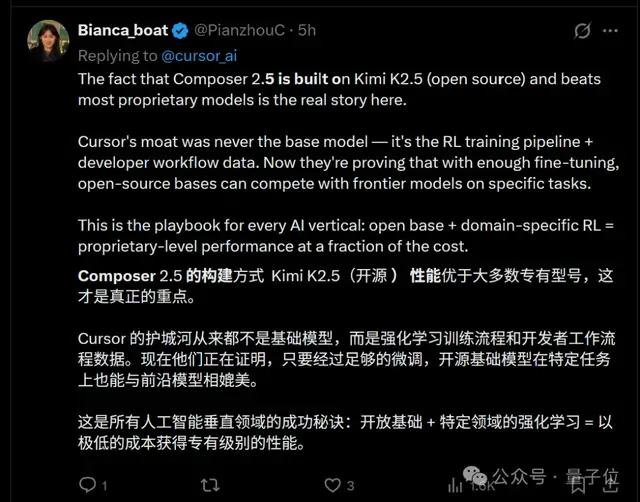
考えてみれば、これは決して大げさではありません。
Composer 2.5 の学習では、Kimi ベースモデルの後段で行われた post-training と RL に総計算量の 85% が使われています。Kimi K2.5 はあくまで出発点にすぎません。本当にコーディングタスクで強くしているのは、実際の IDE シナリオを中心に組まれた Cursor 独自の学習パイプラインです。
これが、Opus の 10 分の 1 まで価格を下げられる理由でもあります。オープンソースのベースモデルを使うことで、最も高価な pretraining をゼロからやる必要がなくなり、残りの予算をコーディング向けの集中的で細かな学習に回せるからです。
モデルは Cursor の IDE シナリオ専用であり、汎用能力にお金を払う必要がないのです。
今回、Musk の SpaceXAI と提携した理由――特に前回はあまり友好的ではなかったのに――も、ロジックはかなり単純そうです。
OpenAI には Codex があり、Anthropic には Claude Code があり、Google には Gemini Code Assist があります。どこも自社でコーディング製品を作っている以上、Cursor にとっては潜在的な競合であり、信頼できる計算資源の提携先にはなりません。
そうなると、Cursor と直接ぶつからずに世界最高水準の計算クラスターを提供できるプレイヤーは、ほとんど残りません。
そして、ちょうど Musk の Colossus 2 が使える状態にあったのです。

さらに少し時間軸を伸ばして見ると、Musk と Cursor の関係は今やかなりもろ