新しいGPUでもなければ、新しいAIアクセラレータカードでもない。
それでも、ある国内GPUベンダーは発表会まるごとを使って、驚くほど物理的なことをやってのけた。
それは、国内初の完全国産の具現化知能シミュレーションプラットフォームを公開したことだ。
まずはデモから見ていこう。

Xiaofeiという名のロボット犬が、ゆっくりとステージに上がってきた。
ステージ中央に到着すると、シミュレーション世界のXiaofeiが側転を披露し、ほどなくして物理世界のXiaofeiもまったく同じ動きを見せた。

向きを変えてもう一度やっても、その動きはまるでコピー&ペーストだ。

Xiaofeiの動作方策はこうだった。
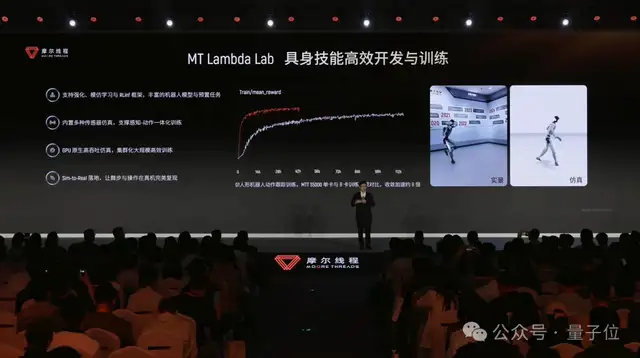
シミュレーション世界だけで100%学習し、損失なく実世界へ移行した。
では、これを実現した国内GPU企業はどこなのか。そして、この具現化知能シミュレーションプラットフォームの名前は何なのか。
もったいぶる必要はない。
それは、Moore Threadsが新たに発表したMT Lambdaだ。

Xiaofeiが先ほどやったことは、要するにこう理解できる。
完全な国産ハードウェアスタックで学習した動作制御方策を、完全な国産エッジチップに初めて全面展開し、実世界で初のSim-to-Real検証を達成した。
これによりMoore Threadsは、中国で唯一、**「大規模モデル学習 — シミュレーション — エッジ展開」**という全工程をつなげられるGPU企業となった。
大規模モデルの台頭が、膨大なインターネットデータを“食べる”ことで進んだのだとすれば、具現化知能の台頭には、極めてリアルな仮想世界が急務となる。
そして今、国内GPUはその世界を自ら構築し始めている。
MT Lambdaを分解してみると、実際にはロボット学習を中心に据えた生産ラインのようなものだ。
上位レイヤーには、MT Lambda-Lab と MT Lambda-Sim の2つのプラットフォームがある。
MT Lambda-Lab は、具現化方策の開発と学習により重点を置き、強化学習、模倣学習、VLAモデルといったタスクを対象とする。
開発者にとって、この層は「エージェントにどうやって行動を覚えさせるか」を解く場所だ。つまり、動作方策を学習し、振る舞いを反復改善し、複雑なタスクでもモデルが徐々に安定していくようにする。
MT Lambda-Sim は、より高忠実度な物理シミュレーションとレンダリングに重点を置き、シーン構築、センサーシミュレーション、データ生成、シミュレーション検証を担う。
ここで問うのは別のことだ。ロボットが見る世界、触れる物体、そして行動後に受け取るフィードバックを、どこまで現実世界に近づけられるか、という点である。
この2つが合わさることで、具現化知能の中核となる開発チェーン、すなわちデータ合成 — 方策学習 — シミュレーション検証 — エッジ展開が形成される。

なぜこのチェーンが重要なのか。理由は単純で、現実世界が高すぎるからだ。
発表会でZhang Jianzhongは、良いエージェントを学習させるうえでの3つの大きな痛点を指摘した。
- 1つ目は、高品質データが大量に不足しており、人手収集や遠隔操作のコストが非常に高いこと。
- 2つ目は、実機での学習は危険かつ高価であり、ロボットやロボット犬が毎日のように転倒して壊れていては困ること。
- 3つ目は、実世界のシナリオは制御しづらく一般化も難しいこと。研究室でうまくいっても、環境が変わればすぐ失敗してしまう。
これらは、具現化知能が今直面している最も現実的な矛盾をよく表している。モデルは高速に進化する一方で、物理的なシナリオの蓄積は遅いのだ。
大規模モデルはインターネットデータを消費できるが、ロボットが消費するのは現実世界のデータである。テーブルの端からカップが滑り落ちる、ロボットハンドが布をつかむ、雨の夜に自動運転車が突然の障害物に遭遇する――こうしたタスクは、単純なテキストでは到底表現しきれない。そこには光、素材、摩擦、衝突、運動軌跡、センサーフィードバックが関わる。ロボットに本当に行動を学ばせるには、こうした複雑なシナリオを、低コストで、大規模に、しかも再現可能な形で生み出さなければならない。
MT Lambdaの基盤能力は、物理、レンダリング、AIの3種類のエンジンを軸にしている。
まず、物理エンジン。
MT Lambdaは、MuJoCo-Warp-MUSAやNewton-MUSAといったオープンソースのバックエンドに加え、Moore Threads独自のAlphaCore物理エンジンも統合している。
MUSAアーキテクチャに基づく並列ソルバを採用し、高精度かつ微分可能な物理計算を支える。一般的なシミュレーションワークロードでは、全体のシミュレーションスループットを約30倍向上できる。
これは何を意味するのか。
ロボットにとって、物理エンジンの価値は画面上で物を動かせることにとどまらない。ロボットアームが変形しやすい物体をつかむとき、指先の接触には力のフィードバックが生じる。四足ロボットが着地するとき、地面の材質によって荷重や姿勢が変わる。自動運転シミュレーションでは、車両・歩行者・障害物の運動関係が現実の物理法則に従わなければならない。シミュレーションが不正確なら、そこで学習した方策は実世界で失敗しやすい。
次に、レンダリングエンジン。
MT Lambdaには、レイトレーシングとハイブリッドレンダリングを組み合わせたMT Photonエンジンが搭載されている。さらに3DGSやMoore Threads独自のAI生成レンダリング機能も導入し、仮想 दृश्यのリアルさ、精細さ、描画効率を高めている。
この部分はとりわけ重要だ。具現化知能は行動を計算するだけでなく、世界を認識しなければならない。カメラ、深度カメラ、LiDAR、触覚センサーといったマルチモーダル入力は、ロボットが環境をどう判断するかに影響する。レンダリングがよりリアルであるほど、合成データは実データに近づき、Sim-to-Realのギャップは小さくなる。
イベントでは、Lightwheel Intelligenceとの協業について語る中で、Zhang Jianzhongは、MTT S5000がRT Coreレイトレーシングエンジンを備え、グラフィックスレンダリング性能を約3倍向上できると述べた。また関連テストでは、MTT S5000のRT Coreによるハードウェアレイトレーシング加速で2.7倍の性能向上が確認された。
最後に、AIエンジン。
MT Lambdaは、PyTorchに深く適合したTorch-MUSAフレームワークに加え、muSolverやmuFFTといった加速ライブラリを統合し、VLAモデルの開発と展開を支援する。同時に、強化学習や模倣学習の学習パラダイムも取り込んでいる。
具現化知能におけるAIエンジンは、ロボットの脳を学習させる部分に相当する。視覚、言語、行動をつなぎ、環境からのフィードバックを次の判断へと変換する。
なぜMoore Threadsは「計算、シミュレーション、レンダリング」をLambda 1つにまとめられるのか?
ここでまさに、フル機能GPUの価値が大きく発揮される。そもそも、中国ではフル機能GPU自体が希少なのだ。
具現化知能がチップに求めるものは、AIの行列演算だけでは到底足りない。
ロボット学習には、VLAモデル、強化学習、模倣学習が必要で、これはAI計算に当たる。衝突、摩擦、動力学、複雑な接触をシミュレートするには、科学計算と物理AIが必要だ。現実的な学習用映像やセンサーデータを生成するには、3Dレンダリングが必要である。さらに将来的には、膨大な動画の取得・転送・生成・再生が関わってくるため、超高精細な動画エンコード/デコードも欠かせない。
TPU、NPU、そして一部のGPGPUは、多くの場合、AI計算や特定種類の汎用計算により特化している。特定の場面では非常に高効率だが、具現化知能はもっと複雑だ。デジタルな脳を学習させ、物理世界を構築し、リアルな映像とセンサー情報を学習ループに取り込む必要がある。
Moore ThreadsがMT Lambdaを物理、レンダリング、AIエンジンを統合したプラットフォームにできたのは、創業以来一貫しているフル機能GPU戦略があるからだ。
Moore Threadsの定義によれば、フル機能GPUとは、自社開発のMUSAアーキテクチャにより、AI計算、グラフィックスレンダリング、物理シミュレーション、科学計算、超高精細動画のエンコード/デコードを1チップ上で支えるものを指す。
言い換えれば、MT Lambdaはバラバラのツールを寄せ集めたキットではない。フル機能GPUと統一されたMUSAアーキテクチャの上に直接構築された、プラットフォームそのものの能力なのだ。
具現化知能にとって、このような計算・シミュレーション・レンダリングの統合は、ロボット学習の実際のニーズにぴったり合う。AIモデルを動かし、物理衝突を計算し、リアルな映像を描画することを同時にこなせるからだ。
以前は、開発者はAI学習、グラフィックスレンダリング、物理シミュレーションをそれぞれ別のハードウェア/ソフトウェアスタックで扱わなければならなかったかもしれない。データをシステム間で往復させる必要があり、非効率で、デバッグも難しく、誤差もたまりやすかった。
MT Lambdaが目指すのは、こうした分断された工程をできるだけ1つの基盤へ戻すことだ。開発者にとって理想なのは、低レベルの適配に振り回される時間を減らし、アルゴリズム、タスク、シナリオそのものにより多くの時間を使えるようにすることにある。
クラウド、エッジ、エコシステムも、いまや閉じたループを作り始めている
MT Lambdaが学習とシミュレーションの問題を解くなら、Moore Threadsのもう1つの取り組みは、クラウド、エッジ、エコシステムのピースも揃えていくことだ。
クラウド側には、KUAEインテリジェントコンピューティングクラスターがある。
大規模モデルの時代には、クラスタはまず学習インフラとして理解される。しかし具現化知能の時代には、巨大なロボット訓練場でもある。シミュレーションデータが大規模化すると、需要は一気に膨らむ。
1本のロボットアームの軌道であっても、複数のカメラ視点、異なる照明、さまざまな素材や外乱の下で映像を生成する必要がある。自動運転の世界モデルなら、週あたり大量のテスト走行距離を生成するかもしれない。ヒューマノイドロボットの学習でも、多数の並列環境で何度も試行錯誤を繰り返す必要がある……
データが数百万、数千万フレーム規模に達すると、基盤計算の役割はアクセラレータから生産ラインへと変わる。
Moore ThreadsのKUAEクラスターの中核加速ユニットには、MTT S5000が含まれる。MTT S5000は第4世代MUSAアーキテクチャ「Pinghu」をベースにし、1枚あたり最大1000 TFLOPSの高密度AI計算、80GBのVRAM、1.6TB/sのメモリ帯域を備える。FP8からFP64までのフル精度計算に対応し、ハードウェアレイトレーシングとAIの学習/推論の両方をサポートする、中国国内でも数少ないGPUの1つでもある。
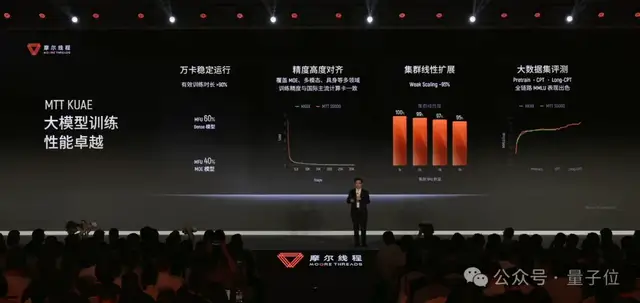
具現化知能の文脈では、こうした仕様の意味はさらに明確になる。FP8、BF16、FP16はAI学習と推論を支え、レイトレーシングは高忠実度レンダリングを支え、物理シミュレーションと科学計算は複雑な動力学の解法を支える。つまり具現化知能には、複数の能力が単一アーキテクチャ上で協調して動くことが求められるのだ。
エッジ側には、長江SoCとE300 AIモジュールがある。
クラウドは大規模学習を担い、シミュレーションプラットフォームは試行と検証を担う。しかし最終的には、その方策はロボット自身の上で動かさなければならない。実世界でロボットが行動する際、応答をすべてクラウドに頼るわけにはいかない。特に低遅延と高信頼性が必要なタスクでは、ローカルでの認識、判断、制御が不可欠だ。エッジ計算は、必ず埋めるべき重要な要素である。
長江SoCをベースにしたMTT E300 AIモジュールは、50 TOPS級のローカル計算を提供し、ロボット端末へ直接搭載でき、低遅延・高信頼性のリアルタイム応答を支える。言い換えれば、学習した経験を