新しい GPU も、新しい智算カードもない。
しかし、ある国産GPUメーカーは、発表会まるごとひとつ分の時間を使って、極めて物理的なことをやってのけた――
エンボディドAI向けの、初のフルスタック国産化シミュレーションプラットフォームを発表したのだ。
まずはその様子を見てみよう。

小飛という名のロボット犬が、ゆっくりとステージへ上がってくる。
ステージ中央に到着すると、スクリーン内のシミュレーション世界にいる小飛が側宙を披露し、続いて物理世界にいる小飛も、まったく同じ動きを見せた。

向きを変えて、もう一度。動きはやはりコピペしたかのようだ。

小飛の運動方針はこうだ。
100% シミュレーション世界で学習し、そのままロスなく現実の物理世界へ移植された。
では、その背後にいる国産GPUプレイヤーは誰なのか? このエンボディドAIシミュレーションプラットフォームの名前は何なのか?
もったいぶる必要はない。
それは、摩爾线程(Moore Threads)が新たに発表したMT Lambdaだ。

先ほどの小飛の一連の動きは、要するにこう理解できる。
これは、初めて完全国産のハードウェアプラットフォーム上で学習した運動制御ポリシーを、完全国産のエッジ向けチップにそのまま展開し、Sim-to-Real(シミュレーションから現実へ)の真機検証を実現したものだ。
これにより、摩爾线程は国内で唯一、**「大規模モデルの学習 — シミュレーション — エッジ展開」**までの全工程をつないだGPU企業となった。
大規模モデルの爆発が、膨大なインターネットデータを“食べさせる”ことで起きたのだとすれば、エンボディドAIの爆発には、極めてリアルな仮想世界が切実に必要になる。
そして今、国産GPUが自ら世界を作り始めたのだ。
MT Lambda を分解してみると、実際にはロボット学習を中心に組み立てられたパイプラインに近い。
最上位にあるのは、2つのプラットフォーム:MT Lambda-Lab と MT Lambda-Sim だ。
MT Lambda-Lab は、エンボディド向けのポリシー開発と学習により重点を置き、強化学習、模倣学習、VLA モデルなどのタスクに対応する。
開発者にとってこの層が解くべき課題は、「知能体にどうやって仕事を覚えさせるか」だ。つまり、行動ポリシーをどう学習させるか、どう反復改善するか、複雑なタスクの中でどう安定性を高めていくか、といった問題である。
一方の MT Lambda-Sim は、高忠実度の物理シミュレーションとレンダリングにより重点を置き、シーン構築、センサーシミュレーション、データ生成、シミュレーション検証を担う。
こちらが気にするのは別の問題だ。ロボットが見ている世界、触れる物体、動作後のフィードバックが、どれだけ現実世界に近づけられるか、という点である。
この2つを合わせると、エンボディドAI開発の主幹となる一本の流れができあがる。データ合成—ポリシー学習—シミュレーション検証—エッジ展開 だ。

なぜこの流れが重要なのか? 理由は、現実世界があまりにも高コストだからだ。
張建中は発表会で、優れた知能体を学習させるうえでの3つの痛点を挙げた。
- まず、大量の高品質データが足りない。人手で集めても、遠隔操作で集めても、コストが高い。
- 次に、実機学習はリスクも代償も大きい。ロボットやロボット犬を毎日何度も転倒させたり壊したりするわけにはいかない。
- 第三に、現実の場面は往々にして制御不能で、汎化もしにくい。実験室では動いても、環境が変わると失敗することがある。
この3点は、まさにエンボディドAI業界が今直面している最も現実的な矛盾を示している。すなわち、モデルの進化は速いのに、物理世界の蓄積は遅いということだ。
大規模モデルはインターネットデータを食べられるが、ロボットが食べるのは現実世界のデータである。机の端からカップが滑り落ちること、布地がロボットハンドでつかみ上げられること、車が雨の夜に突然の障害物に遭遇すること――こうしたタスクは、簡単なテキストだけでは到底言い表せない。そこには、照明、材質、摩擦、衝突、軌道、センサーフィードバックが関わっている。ロボットに本当に行動を学ばせるには、こうした複雑なシーンを、低コストで、大規模に、しかも再現可能な形で生成しなければならない。
MT Lambda の基盤能力は、物理・レンダリング・AI の3種類のエンジンを軸に組み立てられている。
まずは物理エンジン。
MT Lambda は、MuJoCo-Warp-MUSA、Newton-MUSA といったオープンソースのバックエンドに加え、摩爾线程が自社開発した AlphaCore 物理エンジンも統合している。
これらは MUSA アーキテクチャに基づく並列ソルバーを用い、高精度かつ微分可能な物理計算をサポートする。典型的なシミュレーション負荷では、全体のシミュレーションスループットを約 30 倍向上できる。
これは何を意味するのか?
ロボットにとって、物理エンジンの価値は、画面上の物体を動かすことだけではない。ロボットアームが柔らかい物体をつかむときの指先への力の返り、四足歩行ロボットが着地する際に地面の材質によって変わる荷重や姿勢、自動運転シミュレーションにおける車両・歩行者・障害物の運動関係――これらはすべて、現実の物理法則に沿っていなければならない。シミュレーションが不正確だと、学習したポリシーは現実で簡単に破綻してしまう。
次にレンダリングエンジン。
MT Lambda は MT Photon 光子エンジンを搭載し、レイトレーシングとハイブリッドレンダリング能力を融合している。さらに 3DGS と自社開発の AI 生成レンダリング機能も導入し、シミュレーション映像のリアリティ、きめ細かさ、レンダリング効率を高めている。
この部分はとくに重要だ。エンボディドAIは動作を計算するだけでなく、世界を見る必要がある。カメラ、深度カメラ、LiDAR、触覚センサーなど、マルチモーダルな入力がロボットの環境判断に影響する。レンダリングがリアルであればあるほど、合成データは実データに近づき、Sim-to-Real のギャップは縮まりやすくなる。
会場で光輪智能との協業について触れた際、張建中は、MTT S5000 が RT Core レイトレーシングコアを備えており、グラフィックスレンダリング性能を約3倍向上できると述べた。関連テストでは、MTT S5000 の RT Core ハードウェア・レイトレーシング加速レンダリングにより、2.7倍の性能向上が得られたという。
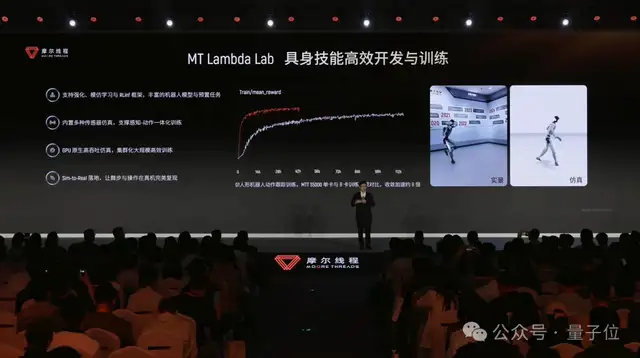
最後は AI エンジン。
MT Lambda は、PyTorch に深く適合した Torch-MUSA フレームワークを統合し、muSolver、muFFT などの高速化ライブラリと組み合わせることで、VLA モデルの開発・展開を支援し、さらに強化学習と模倣学習の学習パラダイムも取り込んでいる。
エンボディドAIに当てはめると、AI エンジンはロボットの“脳”を学習させる役割に相当する。視覚・言語・動作をつなぎ、環境からのフィードバックを次の意思決定へと変換するのだ。
なぜ摩爾线程は「計算・シミュレーション・描画」を Lambda に詰め込めるのか?
実はここに、フル機能GPUの価値が大きく増幅される理由がある。何しろ、国内でフル機能GPU自体が希少なのだ。
というのも、エンボディドAIが求めるチップ性能は、単なるAIの行列計算にとどまらないからである。
ロボット学習では VLA モデル、強化学習、模倣学習を回す必要があり、これはAI演算だ。衝突、摩擦、ダイナミクス、複雑な接触をシミュレートするには、科学計算とフィジカルAIが要る。十分にリアルな訓練映像やセンサーデータを生成するには、3Dレンダリングが必要だ。将来的には大量の動画データの収集、転送、生成、再生も関わってくるが、そこでは超高精細な動画コーデックも欠かせない。
TPU、NPU、あるいは一部の GPGPU 路線は、多くの場合、AI計算や汎用計算の特定領域により特化している。特定のシーンでは非常に高い効率を出せるが、エンボディドAIの課題はもっと複雑だ。デジタルな脳を学習させるだけでなく、物理世界も構築し、実際の映像やセンサーフィードバックもまとめて学習ループに入れなければならない。
摩爾线程が MT Lambda を、物理・レンダリング・AI の3エンジン一体型プラットフォームとして作れたのは、創業以来一貫してフル機能GPU路線を取ってきたからだ。
摩爾线程の定義によれば、フル機能GPUは自社開発の MUSA アーキテクチャを土台に、1枚のチップで AI 計算、グラフィックスレンダリング、物理シミュレーション、科学計算、超高精細動画コーデックを同時にサポートする。
言い換えれば、MT Lambda はバラバラのツール群を無理やり継ぎ合わせたものではなく、フル機能GPUと MUSA の統一アーキテクチャの上に自然に生えたプラットフォーム能力なのだ。
エンボディドAIにとって、こうした**「計算・シミュレーション・描画」の一体化**は、ロボット学習の実需にちょうど合っている。つまり、AIモデルを動かしながら、物理衝突を計算し、リアルな映像を描画する、ということだ。
従来、開発者は異なるハードウェアや異なるソフトウェアスタックを行き来する必要があった。AI学習はあるプラットフォーム、グラフィックスレンダリングは別のプラットフォーム、物理シミュレーションはさらに第三のツール……という具合だ。データはシステム間を行ったり来たりし、効率は悪く、デバッグも難しく、誤差も蓄積していく。
MT Lambda が目指すのは、こうした断絶した工程をできるだけ同じ土台に戻すことだ。開発者にとって理想なのは、下回りの適合作業に時間を取られず、アルゴリズム、タスク、シーンそのものにもっと集中できることだろう。
クラウド、エッジ、エコシステムも閉ループに入りつつある
MT Lambda が学習とシミュレーションの問題を解くものだとすれば、摩爾线程のもう一つの軸は、クラウド、エッジ、エコシステムを一緒に埋めていくことにある。
クラウドは、夸娥(KUAE)智算クラスタだ。
大規模モデルの時代には、クラスタはまず学習基盤として理解された。しかしエンボディドAIの時代になると、それは巨大なロボット訓練場のような存在にもなる。シミュレーションデータが規模化した瞬間、需要は一気に膨らむからだ。
1本のロボットアームの軌道を生成するにも、複数のカメラアングル、多様な照明、多様な材質、多様な摂動下での映像が必要になる。自動運転の世界モデルでは、毎週、膨大なテスト走行距離が生成されるかもしれない。ヒューマノイドロボットの学習でも、大量の並列環境で試行錯誤を繰り返す必要がある……
データが百万フレーム、千万フレーム規模に入ると、底層の計算資源はアクセラレータから生産ラインへと役割を変える。
摩爾线程の夸娥智算クラスタの中核加速ユニットは MTT S5000 だ。MTT S5000 は第4世代 MUSA アーキテクチャ「平湖」をベースにし、単体での AI 演算性能は最大 1000 TFLOPS、80GB のメモリ、1.6TB/s のメモリ帯域を備える。FP8 から FP64 までのフル精度計算に対応し、国内でも極めて少ない、ハードウェアレベルのレイトレーシングと AI の学習・推論を両立できる国産GPUでもある。
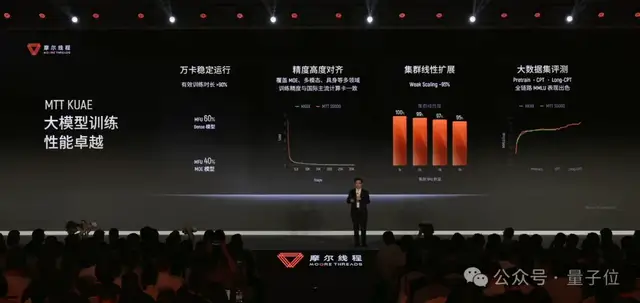
こうした指標はエンボディドAIの文脈で見ると、意味がよりはっきりする。FP8、BF16、FP16 などの能力は AI の学習・推論を支え、レイトレーシングは高忠実度レンダリングを支え、物理シミュレーションと科学計算の能力は複雑なダイナミクスの解法を支える。つまり、エンボディドAIでは複数の能力が同一アーキテクチャ内で連携する必要があるのだ。
エッジ側は、長江 SoC と E300 AI モジュールだ。
クラウドは大規模学習を担い、シミュレーションプラットフォームは試行錯誤と検証を担う。しかし最終的には、ポリシーはロボット本体で動かなければならない。現実世界で行動するロボットは、多くの場合、クラウドの応答だけに頼ることはできない。感知、判断、制御をローカルで完結させる必要がある。特に低遅延・高信頼性が求められるタスクでは、エッジ側の計算資源は不可欠だ。
長江 SoC ベースの MTT E300 AI モジュールは、50 TOPS 級のローカル演算能力を持ち、ロボット端末へ直接搭載できる。低遅延かつ高信頼なリアルタイム応答に対応する。言い換えれば、クラウドで学習した経験を、エッジモジュールがロボットの即時反応へと変えるのだ。
こうして、より完全な閉ループが形成される。クラウドが大規模学習と並列シミュレーションを担い、MT Lambda がポリシー開発、データ合成、シミュレーション検証を担い、E300 AI モジュールが学習結果をロボット端末に持ち込んで実行する。
さらに重要なのは、摩爾线程のこの布陣がすでに実際のエコシステム検証に入り始めていることだ。
たとえば智源との協業では、RoboBrain 2.5 が MTT S5000 の千枚規模クラスタ上でエンドツーエンド学習を完了した。関連検証結果によると、その学習 Loss の推移は H100 クラスタの結果と非常に高い一致を示し、差異はわずか 0.62% だったうえ、一部タスクではより良い性能も示した。さらに、クラスタを 64 枚から 1024 枚へ拡張し、90% 超の線形スケーリング効率を実現した。
こうした結果が示すのは、国産計算クラスターがエンボディドモデル学習の土台として実用可能である、ということだ。
また光輪智能との協業は、よりシミュレーションデータの量産に向いている。双方は摩爾线程のフル機能GPUと夸娥智算クラスタを基盤とし、光輪智能の「解く—測る—生成する」を一体化したシミュレーションプラットフォームと組み合わせ、高信頼なシミュレーションデータ合成ソリューションを共同で構築した。光輪智能の高精度GPU物理ソルバーは MUSA アーキテクチャに適合しており、剛体、柔体、流体、粒子などの複雑な物理過程を高精度かつリアルタイムにシミュレートできる。関連事例では、核心となる物理パラメータのシミュレーション精度が 99% 超に達している。
小馬智行との協業は、対象領域を自動運転へと広げる。両社は MTT S5000 と夸娥智算クラスタを基盤に、世界モデルおよび車載モデル学習の適配と検証を進めている。小馬智行の世界モデルは、毎週 100 億キロメートル超のテストデータを生成でき、そこから多数の極端シナリオも派生する。自動運転にとって、ロングテールシナリオや極限的な危険状況、安全性検証こそ、まさにシミュレーションが最も力を発揮する領域だ。
このほか、摩爾线程は五一視界、光線云などのパートナーとともに、フィジカルAIシミュレーション体系やエンボディドシミュレーションプラットフォームの構築も進めている。4DGS モデルの学習・推論、合成データ生成、タスクライブラリ、シミュレーション計算、仮想と現実の検証ループ――いずれも本質的には同じ問いに答えている。エンボディドAIは、1社だけで閉じて作れるものではなく、計算資源、シミュレーション、アルゴリズム、シーン提供者がそろって初めてエコシステムが回るのだ。
この点こそ、今回の摩爾线程の発表で特に注目すべきところだろう。
それは物語を「私は1枚のチップを持っている」から、**「私は基盤インフラ一式を構築できる」**へと進めたからだ。
下層の MUSA アーキテクチャとフル機能GPUを土台にプラットフォームを積み上げ、エッジへつなぎ、横方向にエコシステムを広げる。このやり方が一夜にして産業地図を塗り替えるわけではないにせよ、国産GPUの戦場を大規模モデルの学習・推論から、物理AIの基盤インフラへと一歩進めたことは確かだ。
目指すべきは、国産エンボディドAI基盤インフラだ
エンボディドAIが今抱える大きな矛盾は、モデルは速く進化するのに、シーンはなかなか追いつかないことだ。
デジタル世界では、大規模モデルは膨大なテキスト、画像、動画データをもとに進化し続けられる。しかし物理世界では、ロボットがドアを開け、箱を運び、柔らかい物体をつかみ、複雑な交差点を通過するたび、その背後にはすべて現実のコストがある。
実機データ収集は高い、遠隔操作は遅い、設備破損のリスクは大きい、危険なシーンはむやみに試せない、ロングテールケースは網羅しきれない。だからこそ、シミュレーション合成データと Sim-to-Real の閉ループが、エンボディドAIが研究室から産業へ進むための鍵となるインフラになる。
「世界を作ること」が、エンボディドAI競争の核心命題になるのはそのためだ。
ここでいう世界の価値は、ゲームのように見栄えが良いことではない。ロボットを学習させ、検証し、行動を修正できることにある。光照明、材質、衝突、摩擦、センサー雑音を反映できるだけのリアルさが必要であり、同時に大規模並列でデータを生成できる効率も必要だ。さらに、さまざまなモデル、ロボット、シーンが接続できる開放性も求められる。
この観点から見ると、摩爾线程の強みは、単一の性能指標だけで語れるものではない。その**「フル機能GPU + MUSA エコシステム」**という技術路線こそが、エンボディドAIの複合的な要求に本質的に近い。
フル機能GPUは AI 計算、グラフィックスレンダリング、物理シミュレーション、科学計算、動画コーデックなど多様な能力を提供する。MUSA は統一されたソフトウェアエコシステムを提供する。MT Lambda は物理・レンダリング・AI の3エンジンを統合する。夸娥智算クラスタは大規模学習とシミュレーションを担う。長江 SoC と E300 AI モジュールは能力をエッジへ届ける。外部のエコシステムパートナーは、データ、シーン、シミュレーションプラットフォーム、業界アプリケーションを補完する。
この流れの価値は、エンボディドAIが本質的にシステム工学だからだ。
大規模モデル企業はまずデジタルな脳を競えばよいかもしれないが、ロボット企業が最終的に向き合うのは、脳がどう身体を制御するか、身体がどう環境を理解するか、環境をどう低コストで再現するか、という問題である。より低コストで、より高効率に、ロボットにとって十分リアルで十分制御可能、かつ十分大規模な訓練世界を作れる者が、エンボディドAIをデモから本当の生産ライン、道路、家庭、都市空間へと持っていける可能性が高い。
もちろん、国産エンボディドAI基盤インフラの構築は一朝一夕には進まない。
シミュレーションのリアルさ、Sim-to-Real の移行効果、開発者エコシステムの成熟度、産業顧客による大規模採用など、どれも継続的な検証が必要だ。摩爾线程のこのソリューションがどこまで行けるかも、今後さらに多くの実案件、多くの開発者、多くのロボット本体からのフィードバック次第だろう。
だが少なくとも今回の発表会を見れば、国産GPUは新しい段階に入った。
それは、「あのカードの代替になれるか」を問う受け身の物語から抜け出し、新たな計算シーンを自ら定義し始めたということだ。発表会でアップデートされた“小麦”はデジタル知能体、宙返りを披露したロボット犬“小飛”は物理知能体である。AIが画面の中から現実へと出ていき、知能体が「話せる」だけでなく「動ける」ようになるとき、基盤計算資源はモデル、グラフィックス、物理を同時に理解しなければならない。
張建中はイベントで、摩爾线程の製品が夸娥から長江へと広がり、あらゆる知能体を支えられるようにしたい、と語っていた。
エンボディドAIの文脈でこれをより具体的に言い換えるなら、クラウドには大規模訓練場があり、シミュレーションには仮想世界があり、エッジには“小脳”としての実行機能があり、エコシステムには現実のシーンがある、ということだ。
大規模モデル競争が「より強いデジタルな脳を誰が学習できるか」を競うものなら、エンボディドAI競争ではもう一つ問われる。誰が先に、十分にリアルな訓練世界を作れるかだ。
今回は、国産GPUがすでにその世界づくりに本格参入し始めた。