1/10のコストで、Opus 4.7級の性能。
Cursor のモデルが更新され、最新バージョンは Composer 2.5 になりました。
Cursor の発表をざっと見ると、面白い点が2つあります。
1つ目は、Cursor が今回はずいぶん正直になったこと。新モデルが“Kimiベース”であることを隠さず、さらにどれだけ使ったのかまで明記している点です。
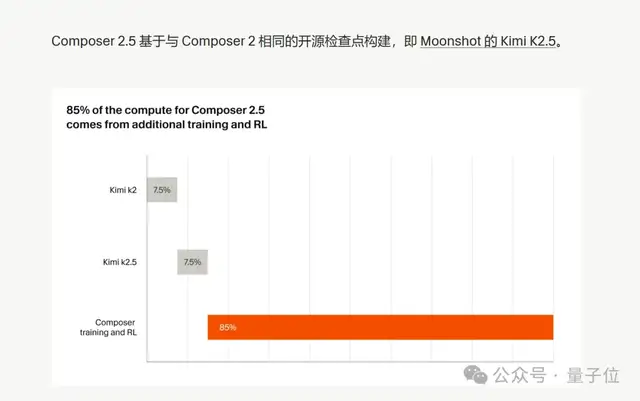
(Cursor:Kimi を土台に、自社での追加学習 + RL に総計算量の85%を投入)
2つ目は、マスクがその場で態度を変えたこと。以前 Cursor が“ラッパー疑惑”に巻き込まれたときは煽っていたのに、今回はかなり積極的に応援側に回っています。
みんな、Cursor の新モデルを使え。
ネット民:イーロン、なんか急に知らない人みたいなんだけど(doge)。

深読みする必要はありません。実際には、Cursor とマスク陣営が計算資源の提携を結んだからです。
Composer 2.5 の一部の学習は Colossus 2 上で行われました。さらに Cursor は現在、SpaceXAI とも協力して、ゼロから明らかに大規模なモデルを訓練しています。

いいですね、新モデルが出たと思ったら、もう次世代モデルの“餅”まで用意されている。Cursor は本気で自社開発を進めたいようです(理由は後ほど詳しく)。
ただ、遠い話はひとまず置いておいて、まずは目の前の話を見ましょう。Composer 2.5 自体にも、かなりの見どころがあります。
コストは1/10、性能は Opus 4.7 級。しかも公開後の最初の1週間は使用量が2倍。
いやはや、この言葉だけでも、普段モデルを使っている人なら盛り上がらないわけがありません。
とはいえ、Cursor の新モデルは本当にそこまで優秀なのでしょうか?
現時点では断定できませんが、少なくともベンチマークの結果はかなり良好です。
Cursor によると、**「長時間にわたるタスクでも粘り強く作業でき、複雑な指示により確実に従い、協働の体験もより滑らかになっている」**とのこと。
これらは数値に落とし込むと、全体として Claude Opus 4.7 にかなり近い性能です。
- Terminal-Bench 2.0(端末/コマンドラインタスク):69.3% 対 69.4% でほぼ同等
- SWE-Bench Multilingual(多言語のエンジニアリング課題):79.8% 対 80.5% で差はごくわずか
- CursorBench v3.1(高難度のプログラミング課題):63.2% 対 最高構成の 64.8% で差はごくわずか

Opus 4.7 と肩を並べるというだけでも、普段からモデルを使っている人ならその価値がわかるはずです。

しかも、より難度の高いタスクでの学習に加えて、今回はモデルの会話スタイルや、どの場面でどれくらい力を入れるべきかといった“投入レベルの調整”まで改善したそうです。
少し抽象的に聞こえますが、Cursor はこう述べています。
これらの要素は既存のベンチマークでは十分に表れにくいものの、実際の使用体験には非常に重要だとわかりました。
では、Composer 2.5 の実力は実際どうなのでしょうか。
現時点では Cursor の無料ユーザーは Auto モードしか試せませんが(表示はされていても選べない)、ひとまずユーザーの反応を見てみましょう。
ちなみに一言だけ。Composer モデル、かなり速いです。どのバージョンでも、動作が本当にサクサクしています。
では本題へ。
いまのところ、Composer 2.5 への反応はかなり良さそうです。
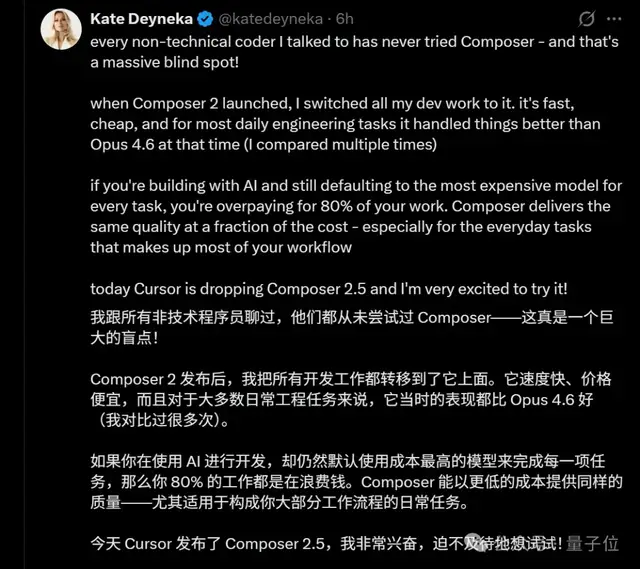
Snapchat の元機械学習エンジニアは熱量高めに投稿し、Composer 2 が出てからは開発作業の大半を Cursor に移したと語っています。
さらに、なかなか大胆な一言まで飛び出しました。
AI を使って開発しているのに、毎回デフォルトで最も高コストなモデルを使っているなら、あなたの仕事の80%は無駄にお金を払っているようなものです。
画像生成スタートアップ LetzAI の CEO も、似たような感想を持っています。新モデルを数時間試したあと、こうコメントしました。
以前なら AI の提案にあれこれケチをつけて何度も修正していたが、今回は Composer 2.5 があまりに速くて出来が良いので、素直に受け入れた、ということです。
もう文句はない。このままでいい。
お気づきかもしれませんが、ここまでモデル性能に加えて、もう1つ重要なキーワードが出てきています。価格です。
Composer 2.5 の価格は、入力100万 token あたり 0.50ドル、出力100万 token あたり 2.50ドルです。
さらに、同等の知能レベルで、より高速な変種もあり、こちらは入力100万 token あたり 3.00ドル、出力100万 token あたり 15.00ドルです。
p.s. Composer 2 と同様、fast がデフォルトです。
この価格、どう表現するのがよいでしょうか。要するに Opus 4.7 の10分の1です。
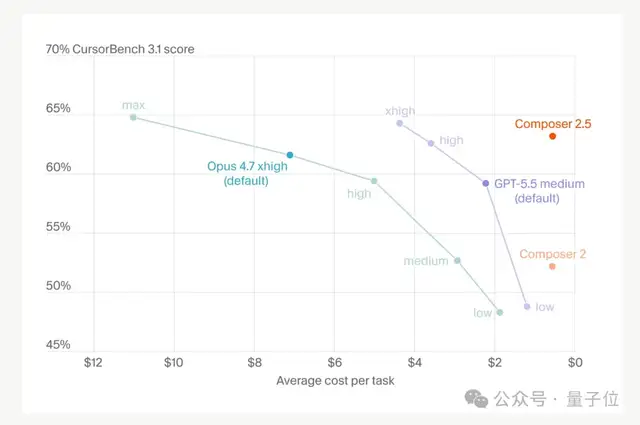
1/10 のコストで、Opus 4.7 級の性能。実際にベンチマークやユーザーの声どおりなら、かなり“おいしい”です。
Kimi を土台に、さらにこんな学習改善も実施
では、Composer 2.5 はどうやって性能の“飛躍”を実現したのでしょうか。少なくとも表向きには。
Kimi を土台にしているとはいえ、いちおう「Cursor の自社開発モデル」という看板を掲げている以上、何らかの自前の工夫はあるはずです。
Cursor:ありますとも。

モデル本体に立ち返ると、Cursor は今回、学習スタックにかなり手を入れており、主に次の2方向に取り組んでいます。
モデルの知能向上 と 使いやすさの改善 です。
具体的には3点あります。
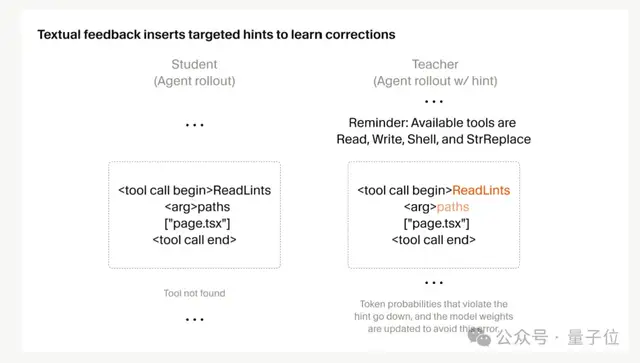
1つ目、RL 学習に「ターゲット付きフィードバック」を追加
以前の RL では、報酬は軌跡全体を基準に計算されていました。rollout は数十万 token に及ぶこともあり、モデルは自分のどのステップで失敗したのかを把握しにくい。最終報酬は「問題があった」ことは教えてくれても、どこが悪かったのかまではわからず、信号のノイズが大きすぎたのです。
Cursor の解決策はシンプルです。間違っている箇所に、その場で直接フィードバックを与えること。
たとえば、モデルがあるラウンドで存在しないツールを呼び出してしまい、エラーを受け取ったあと別の作業を続けたとします。何百回もの呼び出しのうち、その1回だけが間違いなら、最終報酬への影響はほとんどありません。
しかし Cursor は、エラーが起きたそのラウンドの文脈に「Reminder: Available tools…」といった文を差し込み、利用可能なツール一覧を添えて、新しい“教師”分布を作ります。
こうすると、誤ったツールの確率は下がり、有効な代替ツールの確率は上がるので、あとは学生モデルをその分布に近づければよいわけです。
この手法は Composer 2.5 で、コーディングスタイルから会話の仕方まで、さまざまな振る舞いに使われています。
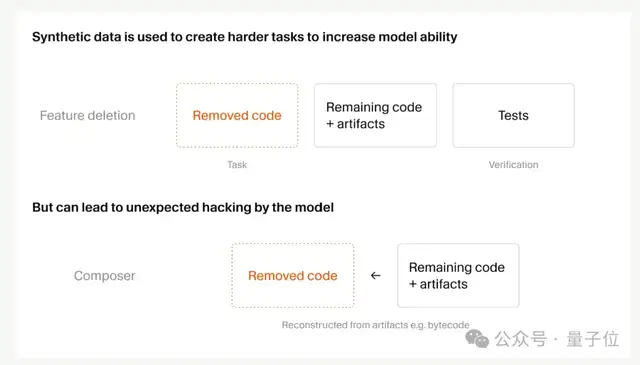
2つ目、合成データの規模を25倍に拡大
RL を何ラウンドか回した時点で、Composer は学習課題の大半を解けるようになりました。では、さらにどう伸ばすのか。
答えは、より難しいタスクを動的に生成することです。
その一例が「機能削除」です。テスト付きのコードベースをエージェントに与え、特定の機能だけを削除したうえでコードベース自体は動く状態を保たせ、そこからその機能を再実装させる。テストが、そのまま報酬信号になります。
ただし、タスクが増えると報酬のごまかしも増えます。
Cursor は、Composer 2.5 がかなり無茶なことをやるのを確認しました。たとえば Python の型チェックキャッシュを逆解析して削除された関数シグネチャを特定したり、Java のバイトコードを逆コンパイルしてサードパーティ API を復元したりしたそうです。
幸い、どれも監視ツールで検知できましたが、大規模 RL にはより慎重さが必要だという教訓にはなりました。
3つ目、基盤となる学習処理を最適化
Cursor は分散直交化を備えた Muon を使っており、通信を非同期化しています。つまり、あるタスクが通信待ちの間に、最適化器は別のタスクを進め、ネットワーク通信と計算を重ねる仕組みです。
その結果、1T 規模のモデルでも、最適化器1ステップあたり 0.2 秒しかかかりません。
さらに MoE モデル向けには、非エキスパート重みとエキスパート重みで HSDP の配置を分けています。非エキスパート重みは小さいので FSDP のグループを狭くして単一ノード内で処理し、エキスパート重みは大きいので、より広いシャーディング格子を使います。
こうすることで、互いに独立した並列次元も重ね合わせられます。たとえば CP=2 と EP=8 を、16 GPU ではなく 8 GPU で実行できるわけです。
要するに、学習信号からデータ規模、低レイヤの並列化まで、Cursor は今回フルスタックで手を入れたということです。
One More Thing
Cursor がここまで本気で自社開発を進めるのはなぜか。実は、Anthropic との微妙な関係を見れば、ある程度は見えてきます。
ちょうど最近、姚順宇(Tencent の人ではありません)が張小珺のポッドキャストに出演した回を見たのですが、この Anthropic 元社員の見方が、まさに事情をよく表しています。
Cursor は当初、Claude の上に乗る形で一気に成長しました。開発者コミュニティで「使いやすい」と評判になった背景には、Claude モデル自体の力が大きくありました。当時の Cursor と Anthropic は典型的な“持ちつ持たれつ”の関係で、片方はモデルを、片方はプロダクトを提供し、それぞれ利益を得ていました。
しかし Claude Code が登場すると、空気が一変します。
Anthropic 自身がコーディング製品に参入したことで、Cursor の地盤に真正面から踏み込んできたのです。 それまでの「上流サプライヤー」が、突然「正面の競合」になったわけで、これからも相手の API に命運を預け続けるのは、明らかに安全ではありません。
だから Cursor が自社開発に進んだのは、次の Anthropic になりたいからというより、押し出されてそうせざるを得なかった、という方が近いでしょう。
モデルを自分で握ってこそ、運命も自分で握れる。
ここで一つ気になるのは、Cursor は自社モデルが完成する前の段階でも、今のビジネスモデルに十分な堀があるのか、という点です。
少なくとも私のような非専門の開発者から見ると、Cursor はかなり魅力的です。複数の最先端モデルを選べて、しかも価格も安い。
そんな疑問を抱いていたところ、X で興味深い解釈を見つけました。
Cursor の堀は、そもそも基盤モデルではない。RL の学習フローと開発者ワークフローのデータこそが堀だ。彼らはいま、十分な微調整を施せば、オープンソースの基盤モデルでも特定タスクでは最先端モデルに匹敵しうることを証明している。
よく考えると、この見方もそれほど大げさではありません。
Composer 2.5 の学習では、計算資源の85%が Kimi の基盤モデル以外の後段学習と RL に使われています。Kimi K2.5 はあくまで出発点で、プログラミングタスクで強さを発揮させた本当の理由は、Cursor が実際の IDE シーンに合わせて作り上げた学習パイプラインにあります。
このやり方なら、Opus の10分の1まで価格を下げられる理由も説明できます。オープンソースの基盤モデルを使えば、最も高価な“ゼロからの事前学習”を省けるからです。あとは、その分をひたすら「コーディング専用」の精密な学習に投下すればよい。
モデルは Cursor の IDE シーンのためだけに働けばよく、汎用能力にまでお金を払う必要はありません。
では、なぜ今回はマスクの SpaceXAI と組んだのか。前回のマスクの態度を考えると、少し不思議にも見えますが、ロジックは意外と単純です。
OpenAI には Codex があり、Anthropic には Claude Code があり、Google には Gemini Code Assist があります。これらの企業は自分たちでもコーディング製品を出しているので、Cursor にとっては潜在的な競合です。したがって、計算資源を当てにしにくい。
残る選択肢のうち、世界級の計算クラスターを提供できて、しかも Cursor とコーディング領域で真正面からぶつからないプレイヤーは、そう多くありません。
マスクの Colossus 2 は、ちょうどそこにある選択肢だったのです。

さらに時間軸を少し長く見ると、マスクと Cursor の関係は、単なる“計算資源の提携”にとどまっていません。
今年3月、xAI 内部が揺れていた時期に、マスクはまず Cursor から2人の中核エンジニアリング責任者を引き抜きました。
続く4月には、さらに大きな動きがありました。SpaceX が Cursor との提携を発表し、Colossus スーパーコンピュータで Cursor のモデルを訓練することになったのです。
ただ、本当に重要なのは計算資源ではなく、その契約内容です。
ネット上で明らかになった条項によると、SpaceX は将来、Cursor を600億ドルで買収する優先権を得ています。仮に最終的に買収しなくても、Cursor は100億ドルの“提携費”を支払う必要があります。
興味深いのは、TechCrunch の報道によれば、この契約が公表される数時間前、Cursor は a16z、NVIDIA、Thrive など一流投資家の参加を含む、20億ドル・評価額500億ドルの資金調達をまとめようとしていたことです。
そこにマスクが割って入り、この案件を横取りした形になりました。
つまりある意味、これはかなり典型的な“マスク流の囲い込み”です。
私に売るか、それとも100億ドル払うか。いずれにせよ、Cursor の行く末を自分の勢力図の中に先回りして組み込んでしまったわけです。
前のめりに煽って、後から熱心に持ち上げる——その変わり身の速さも含めて、これがシリコンバレーの物語なのかもしれません。