The robots working in SF Express and postal warehouses just happened to take first place in embodied “college entrance exam”
 Tian, Yanlin 2026-05-21 12:40:28 Source: QbitAI
Tian, Yanlin 2026-05-21 12:40:28 Source: QbitAI
The RoboChallenge leaderboard has changed hands, and a Tsinghua-backed player has been crowned champion.
Written by Tian Yanlin, from Aofeisi
QbitAI | Official account QbitAI
Right now, the embodied intelligence industry is undergoing a very clear shift.
Robot companies around the world are all rushing toward “real-world competition” at the same time.
Just the other day, Figure kicked off a 7×24-hour livestream with a logistics sorting demo.
Physical Intelligence has also kept running experiments where robots handle all kinds of household chores. As for Tesla’s Optimus, Musk has repeatedly stressed that it should do “useful work.”
The whole industry is gradually coming to understand one thing more and more clearly.
In the robot era, what matters is no longer whose demo is flashier, or whose robot performs more convincingly.

It is whether it can go deep into the physical world and actually get work done.
Once robots enter real environments, the problem changes completely.
Tables are reflective, floors are dirty, objects get occluded, and errors accumulate in every motion.
What looks like simple work on the surface — wiping a table, grasping a package, placing an object — is actually a comprehensive test of perception, planning, control, and memory.
Every company says its robot is a hard worker. So who is actually the best at working?
To be fair, the models need to be taken out into the real world and put head-to-head.
The latest development is that the ranking of the world’s largest embodied-intelligence real-robot evaluation platform, RoboChallenge Table30, has been updated again.
As a result, the competitive landscape in the industry has become instantly clearer, and the gap in capability is now obvious.
Taking the top spot is a model from a Tsinghua-linked embodied robotics company — Era0, the embodied model developed by Xingdong Jiyuan. With a success rate of 64.33% and an overall score of 76.34, it has claimed No. 1 in the world.
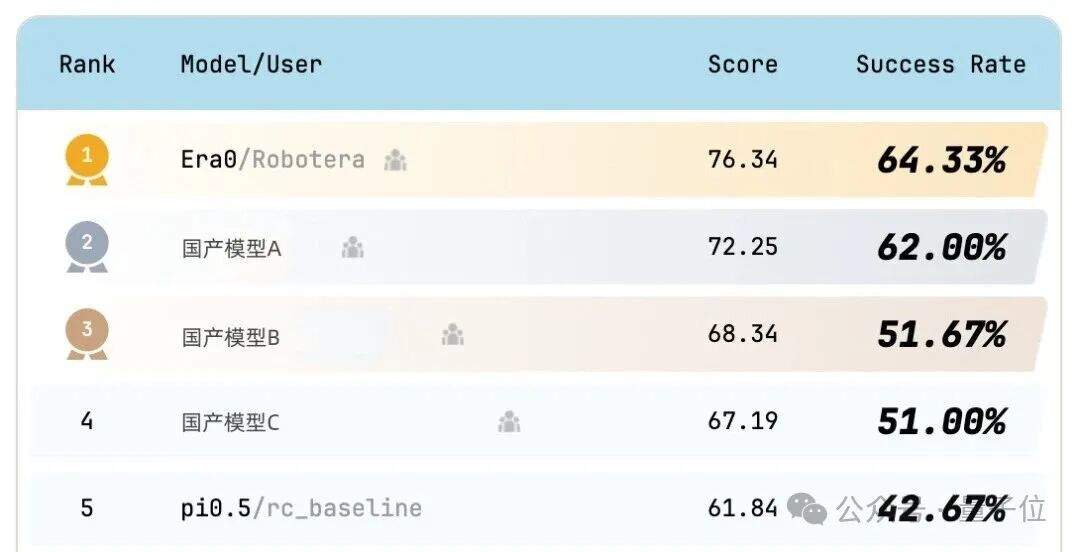
To put it a little proudly: this was not just a model that scored well in one isolated area. Across all 30 tasks, Xingdong Jiyuan’s Era0 achieved SOTA on 17 of them and set a new leaderboard record.
These tasks may look unrelated at first glance, but in the end they are all testing one thing:
the embodied brain’s ability to keep “working” in the physical world.
Topping the toughest ranking in embodied intelligence
RoboChallenge is the industry-recognized “college entrance exam” for real robots.
Not only has it been adopted by the ICRA 2026 Competition, it has also been incorporated into the CVPR 2026 Workshop Competition (GigaBrain Challenge Track), earning official recognition from top international robotics and computer vision conferences.
Winning first place on RoboChallenge means the model has passed the real-world exam room.
That makes it extremely attractive to embodied-intelligence players.
Whether it is Physical Intelligence’s π0/π0.5, Microsoft’s CogACT, or OpenVLA, the world’s leading VLA models often clash fiercely on this leaderboard.
And this time, the competition was just as intense. The data tell the story:
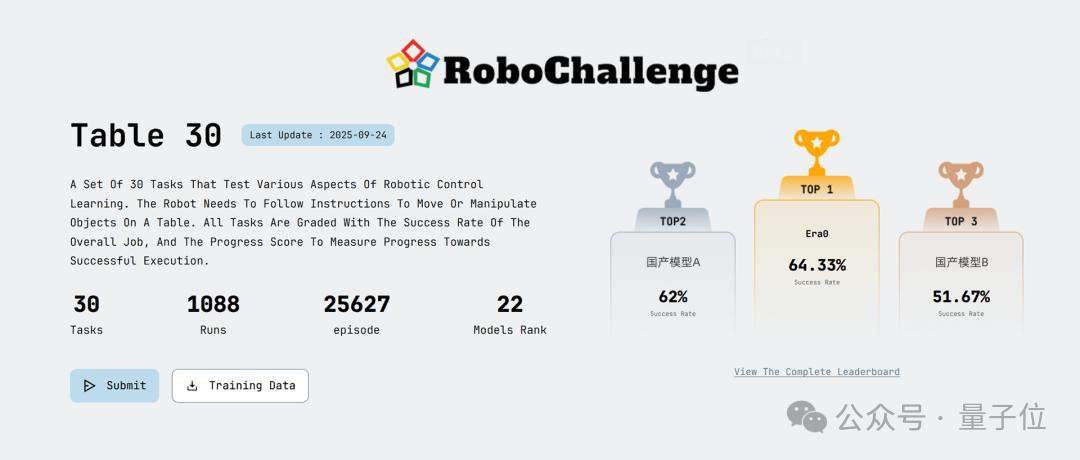
There were 22 competing models, 1088 total execution runs across 30 tasks, and a total of 25627 episodes.
This was not a handful of demo videos. It was continuous testing on real robots.
Among them, two tasks have drawn especially strong attention from the industry:
- make vegetarian sandwich
- wipe the table
Why? Because they are just too hard.

First, the sandwich-making task.

It looks like a little kitchen mini-game, but in reality it tests long-horizon task planning.
The robot not only has to know what to pick up first and what to put down later, it also has to remember how far it has progressed.
Put the bread in the wrong order, forget an ingredient, or get stuck in a motion loop — and the entire task fails on the spot.
At its core, this is not a test of whether the robot can “grasp” something. It is a test of whether it can understand the overall workflow like a human.
Next, the table-wiping task.

At first glance, it seems routine. But every object involved is white: a white piece of paper wipes a white table, and the used paper is thrown into a white trash bin.
This requires visual recognition, long-horizon planning, contact control, and memory of the environment state all at once.
What’s more, dirt on real tables is not a standardized target.
It may be tiny, scattered randomly, shifted in position, or even misread by the robot as already cleaned because of reflections, shadows, or occlusion.
For a long time, these two task types were basically synonymous with the ceiling of embodied-model capability.
But Xingdong Jiyuan’s Era0 broke through both of these hard problems at once.

On make vegetarian sandwich, Era0 achieved a 20% success rate, and among the top 8 models, it was the only model with a non-zero score on this task.

On wipe the table, Era0 reached a 60% success rate, and again it was the only top-8 model to achieve a non-zero result.
In addition, Era0 recorded a double perfect score — 100% success rate with a process score of 100 — on these two tasks:
- put opener in drawer
- turn on faucet

This means Era0 did not merely succeed by luck once or twice; it can execute stably across different tasks, different objects, and different interaction environments.
A closer look shows that the evaluation criteria for the 30 tasks on the leaderboard are extremely broad and comprehensive.
Across several core dimensions of dexterous manipulation — bimanual coordination, flexible object manipulation, multi-view perception, classification tasks, and long-sequence tasks — Era0 ranked first in all of them.
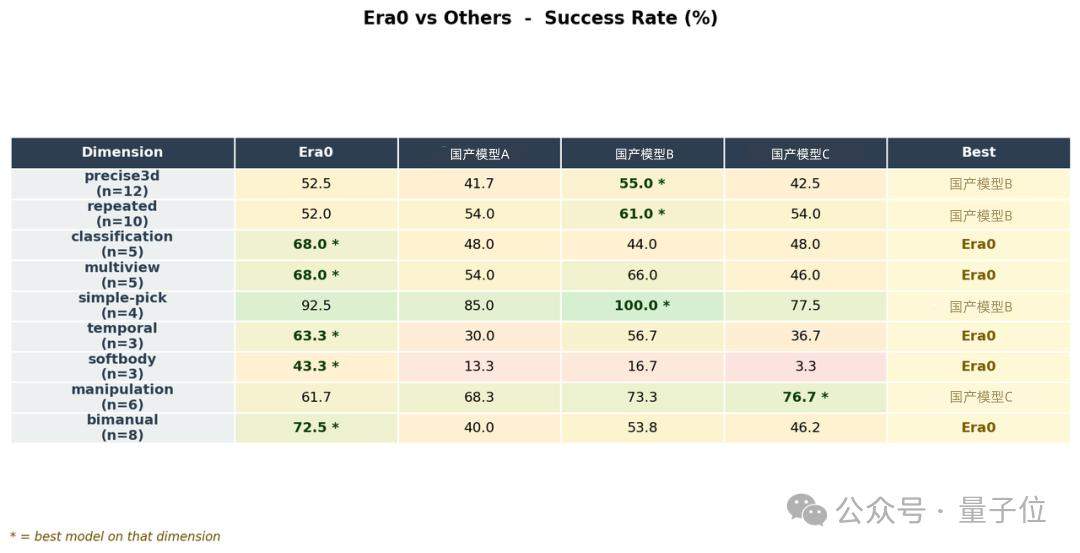
Why did Era0 win?
Behind Era0’s domination of the leaderboard, what the industry should really pay attention to is not the scores themselves.
It is Xingdong Jiyuan’s highly imaginative technical path.
The company did not simply follow the traditional VLA playbook, nor did it just add a World Model on top.
It deeply fused the two.
In fact, very few teams in the industry have truly managed to do this well.
The reason is simple. Over the past two years, VLA did for a time become the mainstream answer in embodied intelligence.
By jointly modeling vision, language, and action, people hoped to give robots the world understanding of large models. But the problems soon became increasingly obvious.
First, weak long-horizon planning.
Many robots can manage the “next move,” but real tasks are not one-shot decision problems — they are like a continuous drama.
A robot must know not only what to do next, but also which stage it is currently in and what will happen later.
Second, hallucinations.
The model may think it has completed the action, but in the real physical world the object may not actually have been lifted, or the dirt may still not have been wiped away.
And most importantly, it lacks continuous state understanding.
 △AI generated
△AI generated
If you want a robot to keep “working” in the physical world, it needs at least three layers of capability.
Layer 1: It must see accurately and localize stably.
The real world has no ground-truth image. Low light, stacking, and reflections are everyday realities.
Many models do not fail because they cannot grasp the object, but because they cannot even see it properly.
What is needed is not the fantasy of “seeing everything at a glance,” but a reliable executor that can identify things correctly and localize them correctly every time.
Layer 2: It must reason coherently and move ahead.
In other words: temporal memory + long-horizon planning.
For multi-step, ordered tasks, it must not get lost or loop endlessly; it has to follow the procedure all the way through.
Layer 3: It must control stably and deploy smoothly in the field.
That means robust real-robot execution, strong generalization and transfer, and fast learning iteration.
And users may not actually want a one-hit wonder. What they want is often a steady, dependable engineer — someone with stable motion, low error, and the ability to work at scale.
 △AI generated
△AI generated
To achieve all this, a VLA that relies only on imitation learning is not enough.
The problem is that it may seem to know, without truly understanding why.
For example, traditional VLA lacks a grasp of physical causality. It can imitate the sequence of demonstrated actions, but it cannot understand the physical logic, spatial relations, or interaction principles behind those actions. It does not know why the operation should be performed.
If the environment, the material’s posture, or the workspace changes even slightly, the existing motion will quickly break down and cannot adapt flexibly.
At the same time, because it does not understand action causality, it cannot predict operational risks or estimate the outcome of its behavior. That makes autonomous error detection and transfer to new scenarios difficult, leaving it able only to follow preset patterns.
Imitation learning alone has a natural ceiling. It cannot meet the practical demand for flexible operations and autonomous evolution required by large-scale deployment.
That is why the best solution is to introduce a World Model.
At its core, this gives robots a way to anticipate the future and plan the next action in advance.
From PAD, the first robot foundation model to natively incorporate a World Model, to VPP, the first embodied World Model policy framework in the world, Xingdong Jiyuan has never treated the World Model as an “add-on feature.”
Video is a more primitive way than language to understand the physical world.
The company believes this is the first principle of every technical path.
The turning point came in January 2025, when Xingdong Jiyuan truly fused VLA and World Model together for the first time.
The release of UP-VLA showed for the first time that both language reasoning and visual prediction can contribute to decision-making.
In effect, it gave robots the ability to “fill in the future in their heads while working.”

But the World Model soon ran into an industry-wide bottleneck: real-robot data is too expensive.
So Xingdong Jiyuan moved on to the next stage — letting the World Model generate data itself.
In October 2025, together with Chelsea Finn’s team at Stanford, it released Ctrl-World, a “controllable generative World Model.”

For the first time in the industry, a World Model was turned into a data simulator.
This allowed robots to keep improving motion accuracy and stability without relying solely on massive amounts of real-robot data.
This January, the company went further and released VLAW, a “VLA policy + World Model co-evolution framework.”
The core idea is to create a two-way data closed loop between Ctrl-World and VLA so that they correct and strengthen each other.
VLA and the World Model have entered a phase of co-evolution.
This is extremely important.
At its core, it changed the way robots learn from the physical world. Instead of teaching robots how to hold a cup, it made them truly understand the act of “lifting” itself.
Looking back, it becomes clear why Era0 showed such strong generalization on complex tasks.
This is not just the victory of a single model; it is a sign that Xingdong Jiyuan’s entire World Model-based technical path is beginning to mature.
Strong capability supports hard work
Beyond its leaderboard results, what stands out most about Era0 is its highly complete capability structure.
Many models have one or two killer features. Era0 is much closer to a truly maturing “embodied execution system,” where perception, memory, control, and execution are beginning to form a closed loop.
And these capabilities map almost directly to real-world work scenarios.
Temporal-memory decision-making: it remembers, and it does not loop
Many robots look quite intelligent at first glance. They can grasp, place, and move.
But once the task gets longer, the weaknesses show immediately: they forget. They forget what step they were on, and may even repeat the same action forever.
That is why long-horizon tasks have always been one of the hardest problems in embodied intelligence.
A robot must know not only what to do next, but also what stage it is in, what has happened so far, and what remains undone.
 △AI generated
△AI generated
One of Era0’s major breakthroughs this time is a short-term temporal memory mechanism.
This allows it to continuously track past actions and task state.
At last, the robot has started keeping “records.”
This capability is especially evident in the vegetarian sandwich task.
The task looks simple, but in fact it is a classic long-horizon temporal-dependency task. Many models suffer a kind of “amnesia” midway through, and their success rate is zero across the board.
Era0 was the only model to complete the full sequence and became the world’s first model to break through this task.
Behind that is the fact that the robot has finally begun to possess true “working memory.”

In logistics scenarios, this becomes even more important.
Real production lines are fundamentally continuous processes: inbound receiving, scanning, sorting, loading — every step is state-dependent.
If the robot cannot remember the stage it is in, it will keep picking up the same parcel again and again, miss items, or sort them incorrectly.
Flexible object manipulation: control gently, grasp firmly
Flexible object manipulation has long been regarded as one of the toughest challenges in embodied intelligence.
That is because many real-world objects are not standard rigid bodies in the first place.
Rags deform, soft-pack items get crushed, paper flutters, and fresh produce slips. If the robot applies even slightly too much or too little force, it can drop, damage, or scatter the object.
By contrast, Era0, through large-scale cross-embodiment pretraining and more precise gripper control, has become capable of handling rigid, flexible, and fragile objects alike.

Its motions are smooth, with minimal shaking.
Most importantly, it has learned how to “feel” the right amount of force.
In flexible-object tasks such as cleaning up paper scraps and folding cloths, Era0 reached a success rate of 43.3%, far above the industry average.
This capability becomes immediately valuable in logistics, produce handling, fresh goods, and retail operations.
In actual warehouses, the hardest things to handle are often not standard cartons, but soft packs, cold-chain products, fresh goods, and expensive fragile items.
These scenarios have long depended on human labor, because it seemed too risky to entrust them to robots.
Real-robot execution robustness: low error, repeatable performance
Another crucial capability to mention is stability.
Many robot demos look very smooth. But what the industry really cares about is one thing: how long can it keep going?
Once a robot enters a factory, it is no longer facing a one-off performance, but 7×24-hour continuous operation.
Motion errors accumulate, and trajectory deviations keep growing.
A robot that looks very clean in the first few minutes may find its errors spiraling out of control after just 30 minutes.
What industry truly lacks is never “can it do it once,” but can it do it stably 10,000 times.
Another core capability Era0 demonstrated this time was very strong real-robot execution robustness.
Behind that are motion interpolation smoothing and optimized real-robot inference.
This showed up especially clearly in high-precision tasks such as transferring fries onto a plate and scanning, where Era0 reached success rates of 90% to 100%.

Its motion trajectories are continuous and smooth, with no obvious shaking or drift.
In other words, it is no longer just “able to move” — it is beginning to exhibit engineering-grade stability.
And that is the most important hurdle before robots can truly enter large-scale industrial deployment.
Not only can it win competitions, it can also go to factories and work
There is a very interesting phenomenon happening in the embodied-intelligence field right now: robot companies around the world are getting better and better at “livestreaming.” Figure is a prime example.
We are not here to debate the value of livestream demos. Logistics sorting itself is not exactly a uniquely impossible operation.
There are already quite a few companies in China that can do it. The problem is that many livestream setups are still highly controlled environments.
Materials are neatly arranged, processes are fixed, and operating conditions are ideal.

But real logistics sites are a completely different story.
Cartons, soft packs, and irregular items are mixed together; lighting, noise, and temperature change constantly; and equipment errors, abnormal operations, and unexpected incidents happen almost every day.
Being able to run continuously in a demo is not the same as being able to enter a real production system.
What the industry truly lacks is not whether something can be shown, but whether it can work stably over the long term.
That is exactly the core advantage Xingdong Jiyuan is trying to build.