Taichu Yuangui Hongyuan: Heterogeneous Computing Capability Will Become a Key Direction for Future AI Computing Infrastructure | AIGC2026
The AI industry has entered a new cycle of high-intensity compute resource consumption
Editorial team’s summary of AIGC2026
QbitAI | WeChat Official Account QbitAI
In 2026, the AI industry has entered a new cycle of high-intensity compute resource consumption.
As applications such as Agentic AI, code assistants, and smart office tools accelerate toward real-world deployment, AI is shifting from demos to actual workflows, and Token is becoming the most important unit of resource consumption in the AI era.
As a result, whether we can secure enough computing power to support more frequent and more complex AI applications has become a critical issue that will determine whether the industry can continue advancing into its next stage. Hong Yuan, Chief Product Officer and Senior Vice President of Taichu Yuangui, said:
As the arrival of the Token economy accelerates, AI computing resources need to offer stronger upward compatibility with frameworks, models, and applications, and provide a more stable, efficient, and user-friendly infrastructure foundation for large-model training, inference, and industry deployment.
As large-model capabilities improve dramatically and AI applications proliferate rapidly, Token invocation demand continues to be released, and domestic compute resources are also迎来 new opportunities for development.
This means that future compute resources will no longer be merely foundational assets behind model training; instead, they will span the entire workflow from model development and application rollout to implementation in industry scenarios, becoming the most important new type of infrastructure in the Token intelligence era.
At this year’s QbitAI AIGC2026, Hong Yuan shared his views on building domestic AI computing foundations, using keywords such as domestic compute resources, Token applications, and the computing efficiency of Agentic AI.

To convey Hong Yuan’s views as fully as possible, QbitAI edited and organized the speech. While preserving the original meaning, we hope it is useful for your reference.
AIGC2026 is an industry summit hosted by QbitAI, bringing together around 20 industry representatives for discussions. More than 1,000 people attended on-site, and the online livestream drew about 4 million viewers, receiving broad attention and coverage from major media outlets.
Key Takeaways
- As Agentic AI, industry-specific large models, and smart applications move into real business scenarios, AI computing is shifting from the stage of “generating content” to “generating tasks,” placing higher demands on stability, efficiency, and collaboration capabilities in computing systems. The challenges ahead lie in coordination across multiple compute units, cooperative scheduling, and reducing waiting and communication costs.
- Domestic AI compute resources are facing new development opportunities, but the real breakthrough will not come from single-node performance alone; it will depend on the service capabilities of large-scale clusters, compute efficiency, and ecosystem usability.
- Training and inference for large models are moving toward clusters of 10,000 GPUs and beyond, requiring compute resource providers to strengthen system capabilities across the full chain, from hardware and interconnects to software, scheduling, and operations and maintenance.
- In Agent task execution, CPU scheduling, GPU computation, communication, and data processing must work together with high efficiency, making heterogeneous computing capability an important direction for future AI computing infrastructure.
- Future AI computing will be like an “oxygen generator” in the Token economy, continuously supporting the operation of models, applications, and industry scenarios.
Below is the full text of Hong Yuan’s speech.
The Arrival of the Token Economy Is Accelerating, Bringing New Opportunities for Domestic AI Compute Resources
Since ChatGPT was released at the end of 2022, the iteration speed of the large-model industry has clearly accelerated. In particular, since the beginning of this year, the update frequency of major large models has increased even further.
For compute resource providers, this means they must continue adapting and optimizing for mainstream large models.
From the number of models, the scale of training data, and the amount of required compute resources, to the parameter scale of the models themselves, all are showing a very clear upward trend.
Against this backdrop, the term Token economy has been mentioned more and more frequently in the industry this year. As the number of large language model invocations grows rapidly, Token has become a highly important unit of consumption in the AI era, and the number of invocations related to domestic models is also continuing to rise.
According to forecasts based on OpenRouter-related data, total Token invocation volume is expected to increase significantly from 2025 to 2026 and on to 2030.
The increase is expected to reach as high as 212 times, and in the future, whether in consumer-facing applications or enterprise and industry applications, much larger Token consumption is expected.
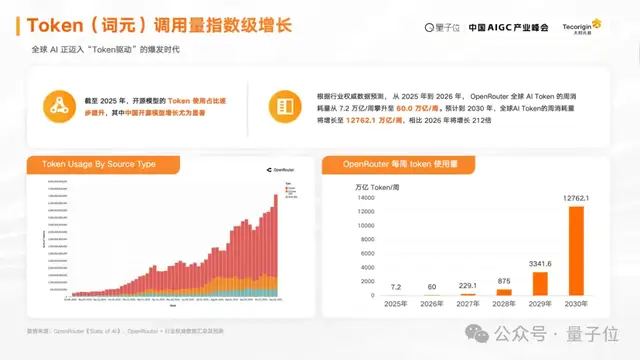
Along with the surge in Token calls, the AI application market is also growing rapidly, and more applications are moving into real-world scenarios. In industries such as office work, code, healthcare, education, energy, and power, the adoption of AI capabilities is accelerating.
This means that the underlying computing infrastructure must support more frequent, more complex, and larger-scale AI invocation demands.
In this process, improvements in compute efficiency will further unlock demand. As production efficiency rises, more application scenarios emerge, invocation frequency increases, and ultimately compute demand continues to grow.
According to data from IDC and some domestic research institutions, by 2030 the global scale of compute resources is projected to grow at an annual rate of 60%, with more than 90% of that expected to be intelligent computing.
For domestic AI compute resources, this represents a very important development opportunity. As large-model capabilities steadily improve, Token demand is rapidly released, and industry applications accelerate toward deployment, domestic compute resources are moving toward a broader range of industrial scenarios.
Large Models Are Entering the Task Era, and AI Compute Faces Three Major Challenges
Of course, before this new opportunity can be fully captured, domestic AI compute resources must also solve several key challenges. Overall, I believe there are mainly three.
The first is the service capability of large-scale clusters.
Today, both training and inference for large models are placing increasingly high demands on cluster scale, with clusters of 10,000 GPUs or even larger becoming the norm. In such large-scale systems, how to ensure training efficiency, system stability, cost control, and reliability is a challenge that compute resource companies must solve.

The second is compute efficiency.
In Agent task execution, when a user enters a task, the system needs to perform task planning, tool invocation, multiple rounds of execution, and result feedback. In this process, the time during which the GPU is actually used for computation accounts for only about 10% of the total, while most of the time is spent on CPU scheduling, communication, and data processing.
The CPU mainly handles serial computation and scheduling, while the GPU excels at parallel computation. Future AI computing systems must achieve higher collaborative efficiency across different compute units such as CPUs and GPUs. Only then can the overall task execution flow become more efficient.
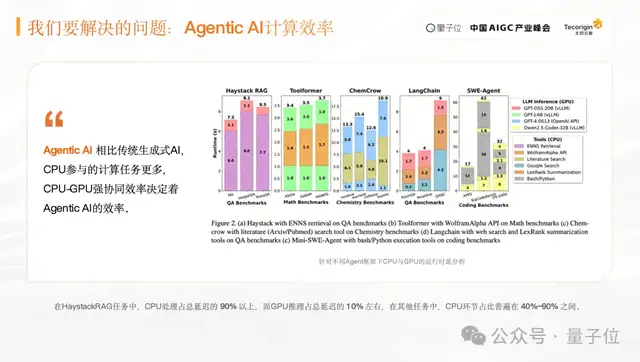
The third is the ecosystem issue.
For domestic compute resource companies, chip design itself is only the first step. What truly determines whether users can actually use the system, whether developers are willing to use it, and whether models and applications can migrate quickly is the software ecosystem behind it.
To support the Token economy well, domestic compute resources must provide ecosystem capabilities that are easier to use and easier to adopt for developers and industry customers. Whether for underlying platform developers or higher-level model and application companies, they need to be able to migrate models, train, fine-tune, and deploy inference more smoothly.
The development of AI computing is no longer just a matter of stacking up performance and compute volume. Especially as Agentic AI develops rapidly, AI computing is shifting from content generation to task generation, which creates new requirements for computing systems. Future AI computing must solve system-level problems such as heterogeneous coordination, high availability, and ecosystem compatibility.
As AI computing moves from the stage of “generating content” to “generating tasks,” the importance of heterogeneous coordination will only continue to grow. What will be needed in the future is collaboration across multiple compute units, coordinated scheduling, and reduced waiting and communication costs.
From Supercomputing Accumulation to Ecosystem Compatibility, Building the AI Industry’s “Oxygen Generator”
In response to these challenges, Taichu Yuangui has also been continuously exploring and practicing.
First, in terms of large-scale clusters, we have many years of technical accumulation in the high-performance computing field. In particular, large-scale parallel computing tasks often require coordinated computation at the scale of 100,000 cores or even several hundred thousand cores, and that experience has become an important foundation for building today’s AI computing clusters.
Second, in terms of heterogeneous computing, we have already laid out the groundwork from the chip design stage.
Our core chip design includes a variety of compute modules, such as modules for general-purpose computing, data processing cores, and modules for parallel computing. These different compute units are connected through an on-chip network, improving collaborative efficiency between different compute units such as CPUs and GPUs.
This architectural design is intended to address the increasing complexity of future AI tasks. AI applications will no longer be limited to single-model inference; they will also include task decomposition, tool invocation, data processing, multiple rounds of interaction, and result feedback. To handle such task chains, the underlying computing system must have stronger collaborative capabilities.
In addition, on the ecosystem side, we believe this is also a very important factor.
At the foundational level, while providing our self-developed programming framework and programming language, we also draw on mature development ecosystems to offer developers more user-friendly ways to build. Developers familiar with Python can also develop using the relevant tools.
On top of that, we are exploring the ability to automatically generate operators based on natural-language interaction, aiming to lower the development barrier for users. For training, fine-tuning, and inference, we want to provide a more complete integrated solution.
At the same time, Taichu Yuangui also provides a range of tool components to help models migrate across different frameworks with one click.
From frameworks to models, we are compatible with multiple third-party framework libraries and model libraries, helping model companies, application companies, and industry customers use domestic compute resources more smoothly.
When the Token economy arrives, compute resources will become to the AI industry what oxygen is to human beings. The new infrastructure we are building is, in essence, like a system that continuously supplies oxygen.
What Taichu Yuangui has been doing, and will continue to do, is working with industrial partners to leverage each other’s strengths, connect upstream and downstream resources, and provide China’s AI industry with a stable, efficient, and independently controllable new generation of computing infrastructure.