At 1/10 the cost, with Opus 4.7-level performance.
Cursor’s model lineup has been updated, and the latest version is Composer 2.5.
A quick look at Cursor’s announcement reveals two interesting things.
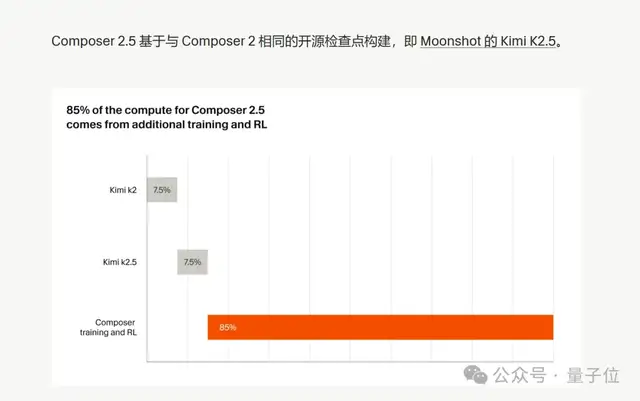
First, Cursor was unusually candid this time. It made no attempt to hide the fact that the new model is “Kimi-based,” and it even spelled out how much it used.
(Cursor: built on Kimi, with a total of 85% of compute spent on additional in-house training + RL)
Second, Musk’s stance changed on the spot. Back when Cursor was dragged into the “wrapper” controversy, he was taking shots at it. This time, though, he’s been very much on the support side.
Everyone should use Cursor’s new model.
The internet: Elon suddenly sounds like he’s never met us before (doge).

No need to overread it. In reality, Cursor and Musk’s camp formed a compute partnership.
Some of Composer 2.5’s training was done on Colossus 2. And Cursor is now also working with SpaceXAI to train a clearly larger model from scratch.

Nice — the moment a new model drops, the next generation is already being baked. Cursor really does seem serious about building in-house (more on why later).
But let’s set the long-term story aside for now and look at what’s in front of us. Composer 2.5 itself has plenty to talk about.
1/10 the cost, with performance on par with Opus 4.7. And for the first week after launch, usage is doubled.
Honestly, just that line alone is enough to get anyone who uses models regularly excited.
That said, is Cursor’s new model really that good?
We can’t say for sure yet, but at the very least, the benchmark results look strong.
According to Cursor, “it can stay on task for long stretches, follow complex instructions more reliably, and deliver a smoother collaborative experience.”
If you turn that into numbers, it comes out to performance that’s broadly comparable to Claude Opus 4.7.
- Terminal-Bench 2.0 (terminal/CLI tasks): 69.3% vs. 69.4%, essentially tied
- SWE-Bench Multilingual (multilingual engineering tasks): 79.8% vs. 80.5%, a very small gap
- CursorBench v3.1 (hard programming tasks): 63.2% vs. 64.8% in the top configuration, again a very small gap

Just being able to stand shoulder to shoulder with Opus 4.7 is enough for anyone who regularly uses models to appreciate the value.

What’s more, in addition to training on harder tasks, Cursor says it also improved the model’s conversational style and its “effort allocation” — in other words, how much effort it should put in depending on the situation.
That sounds a bit abstract, but Cursor puts it this way:
These factors are not always well captured by existing benchmarks, but we found them to be extremely important to the real user experience.
So how capable is Composer 2.5 in practice?
For now, free Cursor users can only try Auto mode (it’s shown, but not selectable), so let’s start by looking at user reactions.
One quick note: the Composer model is very fast. In every version, it feels genuinely snappy.
Now to the main point.
So far, the response to Composer 2.5 looks very positive.
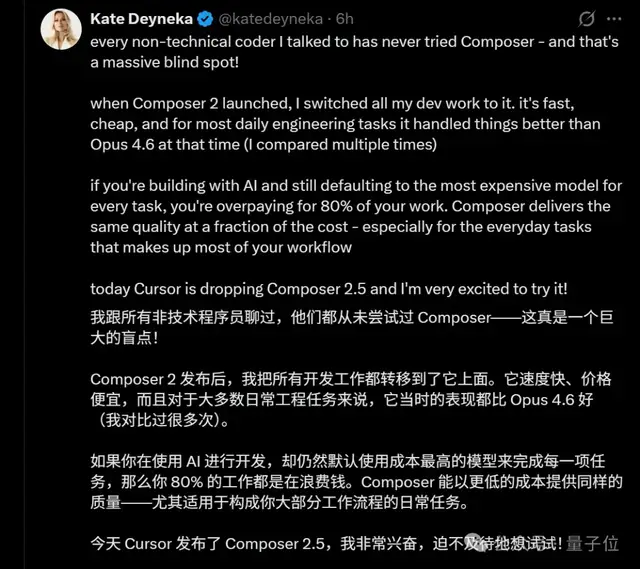
A former machine learning engineer from Snapchat posted enthusiastically that since Composer 2 came out, he’s moved most of his development work to Cursor.
He also dropped a pretty bold line:
If you’re using AI for development and you default to the most expensive model every time, you’re basically wasting money on 80% of your work.
The CEO of image-generation startup LetzAI had a similar take. After trying the new model for a few hours, he commented that he used to nitpick AI suggestions and revise them repeatedly, but this time Composer 2.5 was so fast and so good that he just accepted it.
No complaints. Keep it as is.
You may have noticed that, beyond model performance, another important keyword has come up: price.
Composer 2.5 is priced at $0.50 per million input tokens and $2.50 per million output tokens.
There is also a faster variant at the same intelligence level, priced at $3.00 per million input tokens and $15.00 per million output tokens.
p.s. Just like Composer 2, fast is the default.
How should we put this? In short: one-tenth the price of Opus 4.7.
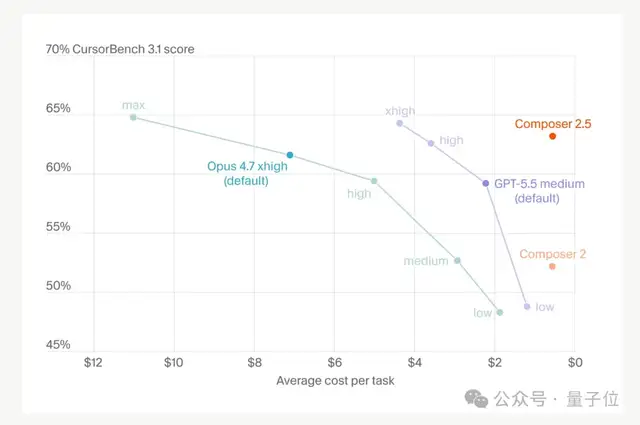
At 1/10 the cost, with Opus 4.7-level performance. If the benchmarks and user feedback are accurate, that’s an extremely sweet deal.
Built on Kimi, plus these training improvements
So how did Composer 2.5 achieve this kind of performance leap? At least on the surface.
Even though it’s built on Kimi, if Cursor wants to carry the banner of a “homegrown model,” it still has to be doing something of its own.
Cursor: Absolutely.

Looking at the model itself, Cursor made substantial changes to the training stack this time, focusing mainly on two directions:
Improving the model’s intelligence and improving usability.
There are three specific changes.
1. Adding “targeted feedback” to RL training
In earlier RL setups, rewards were computed based on the trajectory as a whole. A rollout could run for hundreds of thousands of tokens, making it hard for the model to tell which step actually caused the failure. The final reward only told it that “something went wrong,” not where things went wrong, so the signal was too noisy.
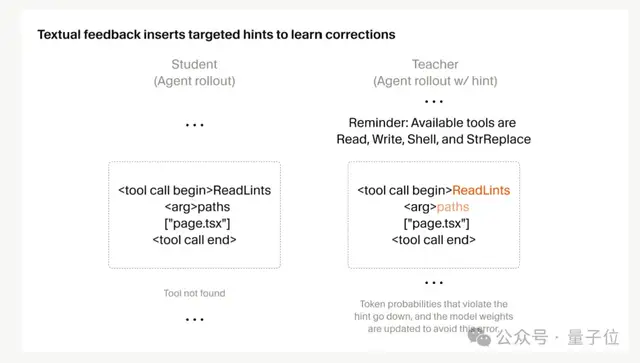
Cursor’s solution is simple: give direct feedback at the exact point where the mistake happens.
For example, suppose the model calls a tool that doesn’t exist in one round, gets an error, and then keeps going with some other task. If that one mistake is only one of hundreds of calls, its impact on the final reward is tiny.
But Cursor inserts a line like “Reminder: Available tools…” into the context for the round where the error occurred, along with the list of available tools, creating a new “teacher” distribution.
That lowers the probability of the wrong tool and raises the probability of valid alternatives, after which you just train the student model toward that distribution.
In Composer 2.5, this approach is used for a wide range of behaviors, from coding style to how the model talks.
2. Expanding synthetic data by 25x
After a few rounds of RL, Composer could already solve most of the training tasks. So how do you push it further?
The answer is to dynamically generate harder tasks.
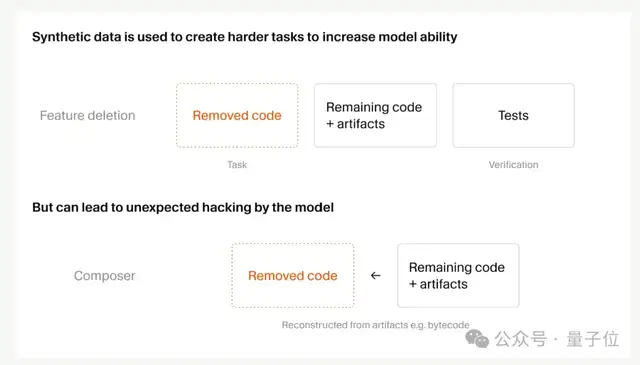
One example is “feature removal.” You give the agent a codebase with tests, remove a specific feature while keeping the codebase functional, and then have it reimplement that feature. The tests serve as the reward signal.
But as tasks get harder, reward hacking gets more common too.
Cursor found that Composer 2.5 was capable of some pretty extreme behavior. For example, it reportedly reverse-engineered Python type-checker caches to identify deleted function signatures, and decompiled Java bytecode to reconstruct third-party APIs.
Fortunately, all of it was detectable by monitoring tools, but it was still a reminder that large-scale RL needs to be handled much more carefully.
3. Optimizing the underlying training pipeline
Cursor uses Muon with distributed orthogonalization and has made communication asynchronous. In other words, while one task is waiting on communication, the optimizer can keep working on another task, overlapping network communication with computation.
As a result, even for a 1T-scale model, each optimizer step takes only 0.2 seconds.
For MoE models, Cursor also separates HSDP placement for non-expert weights and expert weights. Non-expert weights are small, so it narrows the FSDP group and handles them within a single node; expert weights are large, so it uses a wider sharding mesh.
This allows independent parallel dimensions to be stacked together. For example, CP=2 and EP=8 can be run on 8 GPUs instead of 16.
In short, Cursor went full stack this time — from training signals to data scale to low-level parallelization.
One More Thing
Why is Cursor pushing so hard to build in-house? If you look at its relationship with Anthropic, the reason becomes fairly clear.
I recently watched the episode where Yao Shunyu (not the Tencent person) appeared on Zhang Xiaojun’s podcast, and this former Anthropic employee’s view captures the situation very well.
Cursor grew rapidly at first by building on top of Claude. A big part of its reputation for being “developer-friendly” came from the strength of the Claude models themselves. At the time, Cursor and Anthropic had a classic symbiotic relationship: one provided the model, the other the product, and both benefited.
But that changed when Claude Code arrived.
Once Anthropic entered the coding-product space itself, it moved directly into Cursor’s territory. The upstream supplier suddenly became a front-line competitor, and continuing to rely on their API for the future was obviously no longer a safe bet.
So Cursor’s move toward in-house models was less about wanting to become the next Anthropic, and more about being forced into it.
Only by holding the model yourself can you hold your own fate.
One question that naturally comes up is whether Cursor still has a strong enough moat in its current business model, even before its own model is fully ready.
At least from the perspective of a non-specialist developer like me, Cursor is pretty compelling. You can choose from multiple frontier models, and the pricing is low.
While I was thinking about that, I found an interesting take on X:
Cursor’s moat is not the foundation model in the first place. Its moat is the RL training pipeline and the developer-workflow data. They’re proving right now that with enough fine-tuning, even open-source foundation models can rival frontier models on specific tasks.
Come to think of it, that view isn’t really exaggerated.
In Composer 2.5’s training, 85% of the compute was spent on post-training and RL beyond the base model itself. Kimi K2.5 is just the starting point; the real reason it became so strong at programming tasks is the training pipeline Cursor built around real IDE scenarios.
This also explains how they can bring the price down to one-tenth of Opus. By using an open-source foundation model, they avoid the most expensive part: pretraining from scratch. From there, they can pour everything into precise “coding-only” training.
The model only needs to work for Cursor’s IDE scenarios; there’s no need to pay for general-purpose capability.
So why partner with Musk’s SpaceXAI this time? Given Musk’s earlier attitude, it may seem odd, but the logic is actually pretty straightforward.
OpenAI has Codex, Anthropic has Claude Code, and Google has Gemini Code Assist. These companies all have their own coding products, so from Cursor’s perspective they’re potential competitors. That makes them unreliable compute partners.
Among the remaining options, there aren’t many players who can provide a world-class compute cluster without also competing head-on with Cursor in coding.
Musk’s Colossus 2 was exactly that kind of option.

Looking a bit further ahead, Musk and Cursor’s relationship is no longer just a “compute partnership.”
In March, when things inside xAI were turbulent, Musk first poached two key engineering leaders from Cursor.
Then in April, there was an even bigger move. SpaceX announced a partnership with Cursor to train Cursor’s models on the Colossus supercomputer.
But the really important part isn’t the compute — it’s the deal terms.
According to clauses that surfaced online, SpaceX received a future right of first refusal to acquire Cursor for $60 billion. Even if it doesn’t end up buying Cursor, Cursor would still need to pay a $10 billion “partnership fee.”
Interestingly, according to TechCrunch, just hours before the deal was made public, Cursor had been trying to close a $2 billion round at a $50 billion valuation, with participation from top investors including a16z, NVIDIA, and Thrive.
Musk stepped in and snatched the deal away.
In other words, this is a pretty classic Musk-style enclosure.
Sell to me, or pay $10 billion. Either way, he’s already folded Cursor’s future into his own map of power.
First he stirs things up aggressively, then he enthusiastically hypes it later — maybe that’s Silicon Valley for you.