There is no new GPU, and no new intelligent computing card either.
And yet, one domestic GPU maker spent an entire product-launch event doing something intensely physical:
It unveiled the first fully localized end-to-end simulation platform for embodied AI.
Let’s take a look at what that looked like.

A robot dog named Xiaofei slowly makes its way onto the stage.
When it reaches the center, Xiaofei in the simulation world on the screen performs a side aerial, and then Xiaofei in the physical world mirrors the exact same motion.

It turns around and does it again. The movement still looks as if it were copy-pasted.

Xiaofei’s motion strategy is simple:
It learned entirely in simulation, and was then transferred to the real physical world with no loss.
So, who is the domestic GPU player behind this? And what is the name of this embodied AI simulation platform?
No need to drag it out.
It is Moore Threads, which has just launched MT Lambda.

What you just saw with Xiaofei can be understood like this:
For the first time, a motion-control policy trained on a fully domestic hardware platform was deployed directly onto a fully domestic edge chip, enabling real-machine validation of Sim-to-Real (simulation to reality).
With this, Moore Threads has become the only GPU company in China to connect the full pipeline from “large-model training — simulation — edge deployment.”
If the explosion of large models came from feeding them vast amounts of internet data, then the explosion of embodied AI urgently requires an extremely realistic virtual world.
And now, domestic GPUs are beginning to build that world themselves.
If you break down MT Lambda, it is essentially a pipeline built around robot learning.
At the top level are two platforms: MT Lambda-Lab and MT Lambda-Sim.
MT Lambda-Lab focuses more on policy development and training for embodied AI, supporting tasks such as reinforcement learning, imitation learning, and VLA models.
For developers, the core question this layer addresses is: how do you teach an agent to do work? In other words, how do you train action policies, iterate on them, and improve stability across complex tasks?
MT Lambda-Sim, meanwhile, focuses more on high-fidelity physical simulation and rendering, handling scene construction, sensor simulation, data generation, and simulation validation.
Here, the key question is different: how closely can the world the robot sees, the objects it touches, and the feedback it receives after acting resemble the real world?
Together, these two pieces form a main development loop for embodied AI: data synthesis — policy training — simulation validation — edge deployment.

Why is this pipeline important? Because the real world is far too expensive.
At the launch event, Zhang Jianzhong identified three major pain points in training capable agents:
- First, there is a lack of large amounts of high-quality data. Whether collected manually or via teleoperation, it is expensive.
- Second, training on real machines carries high risk and high cost. You cannot afford to knock over or break robots and robot dogs every day.
- Third, real-world scenarios are often uncontrollable and difficult to generalize. A system that works in the lab may fail when conditions change.
These three points capture the most practical contradiction facing the embodied AI industry right now: models are evolving quickly, while the physical world is accumulating experience too slowly.
Large models can eat internet data, but robots feed on real-world data. A cup sliding off the edge of a table, cloth being grasped by a robotic hand, a car encountering a sudden obstacle on a rainy night—these are tasks that simple text cannot possibly express. They involve lighting, material properties, friction, collisions, trajectories, and sensor feedback. To truly teach robots to act, these complex scenes must be generated at low cost, at scale, and in a reproducible way.
MT Lambda’s foundational capabilities are built around three engines: physics, rendering, and AI.
First, the physics engine.
MT Lambda integrates open-source backends such as MuJoCo-Warp-MUSA and Newton-MUSA, as well as Moore Threads’ in-house AlphaCore physics engine.
These use parallel solvers based on the MUSA architecture to support high-precision, differentiable physics computation. Under typical simulation loads, overall simulation throughput can be increased by about 30x.
What does that mean?
For robots, the value of a physics engine is not just moving objects on a screen. When a robot arm grasps a soft object, how force is transmitted to the fingertips; when a quadruped lands, how load and posture change depending on the ground material; in autonomous driving simulation, how vehicles, pedestrians, and obstacles interact dynamically—these all have to follow the laws of real physics. If the simulation is inaccurate, the policy trained in it can easily fail in the real world.
Next, the rendering engine.
MT Lambda is equipped with the MT Photon engine, combining ray tracing and hybrid rendering capabilities. It also incorporates 3DGS and Moore Threads’ own AI-generated rendering features to improve realism, detail, and rendering efficiency in simulation footage.
This part is especially important. Embodied AI does not just need to compute actions; it needs to see the world. Multimodal inputs such as cameras, depth cameras, LiDAR, and tactile sensors all affect how robots perceive their environment. The more realistic the rendering, the closer synthetic data gets to real data, and the smaller the Sim-to-Real gap becomes.
When discussing the collaboration with Guanglun Intelligence at the event, Zhang Jianzhong noted that the MTT S5000 features RT Core ray-tracing cores and can improve graphics rendering performance by about 3x. Related tests showed that the MTT S5000’s RT Core hardware-accelerated ray-tracing rendering delivered a 2.7x performance gain.
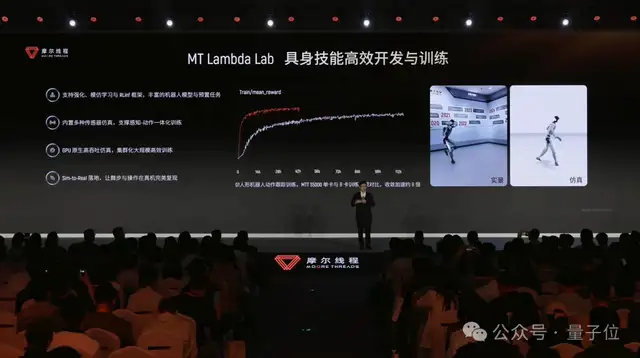
Finally, the AI engine.
MT Lambda integrates the Torch-MUSA framework, which is deeply compatible with PyTorch, and combines it with acceleration libraries such as muSolver and muFFT to support the development and deployment of VLA models, while also incorporating reinforcement learning and imitation learning training paradigms.
In embodied AI terms, the AI engine is responsible for training the robot’s “brain.” It connects vision, language, and action, turning environmental feedback into the next decision.
Why Can Moore Threads Pack “Compute, Simulation, and Rendering” into Lambda?
This is where the value of a full-feature GPU really comes into focus. After all, full-feature GPUs are still rare in China.
That’s because the chip capabilities required by embodied AI go far beyond plain matrix math for AI.
Robot learning needs VLA models, reinforcement learning, and imitation learning—this is AI compute. Simulating collisions, friction, dynamics, and complex contacts requires scientific computing and physical AI. Generating sufficiently realistic training footage and sensor data requires 3D rendering. In the future, large-scale video data collection, transfer, generation, and playback will also be involved, and ultra-high-definition video codecs will be essential too.
TPUs, NPUs, and some GPGPU approaches are usually more specialized in particular areas of AI or general-purpose computation. They can be highly efficient in specific scenarios, but embodied AI is a more complicated challenge. You must not only train a digital brain, but also construct a physical world and feed real visual and sensor feedback into the learning loop.
Moore Threads was able to build MT Lambda as an integrated platform for physics, rendering, and AI because it has pursued the full-feature GPU path consistently since its founding.
According to Moore Threads’ definition, a full-feature GPU is built on its in-house MUSA architecture and supports AI compute, graphics rendering, physics simulation, scientific computing, and ultra-HD video codecs on a single chip.
In other words, MT Lambda is not a patchwork of loosely stitched-together tools. It is a platform capability that grows naturally out of the unified architecture of full-feature GPUs and MUSA.
For embodied AI, this kind of integration of compute, simulation, and rendering aligns perfectly with the real needs of robot learning: running AI models while computing physical collisions and rendering realistic visuals.
Traditionally, developers had to jump between different hardware and software stacks: AI training on one platform, graphics rendering on another, physics simulation on a third. Data bounced between systems, efficiency was poor, debugging was difficult, and errors accumulated.
MT Lambda aims to bring these fragmented stages back onto a common foundation as much as possible. The ideal for developers is to stop spending time on infrastructure adaptation and instead focus more on algorithms, tasks, and the scenes themselves.
Cloud, Edge, and Ecosystem Are Also Moving Into a Closed Loop
If MT Lambda addresses training and simulation, then another of Moore Threads’ priorities is to build out the cloud, edge, and ecosystem together.
On the cloud side is the KUAE intelligent computing cluster.
In the era of large models, clusters were first understood as training infrastructure. But in the era of embodied AI, they also become giant robot training grounds. Once simulation data scales up, demand rises sharply.
To generate the trajectory for a single robotic arm, you need footage from multiple camera angles, under varied lighting, with different materials and perturbations. In autonomous driving world models, billions of kilometers of test data may be generated every week. Humanoid robot training may require trial and error across massive parallel environments…
When data reaches the scale of millions or tens of millions of frames, underlying compute shifts from being an accelerator to becoming a production line.
The core accelerator in Moore Threads’ KUAE cluster is the MTT S5000. Built on the fourth-generation MUSA architecture, “Pinghu,” the MTT S5000 delivers up to 1000 TFLOPS of AI compute, 80GB of memory, and 1.6TB/s of memory bandwidth. It supports full-precision computing from FP8 to FP64, and is also one of the very few domestic GPUs in China that can combine hardware-level ray tracing with AI training and inference.
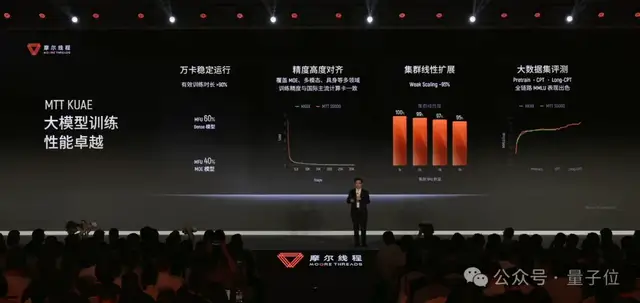
These metrics become much clearer in the context of embodied AI. FP8, BF16, and FP16 support AI training and inference; ray tracing supports high-fidelity rendering; and physics simulation plus scientific computing support solving complex dynamics. In embodied AI, multiple capabilities must work together within the same architecture.
On the edge side are the Changjiang SoC and the E300 AI module.
The cloud handles large-scale training, and the simulation platform handles trial and error plus validation. But ultimately, policies must run on the robot itself. Robots acting in the real world often cannot rely solely on cloud responses. Perception, decision-making, and control must be completed locally. Especially for tasks that require low latency and high reliability, edge compute is essential.
The MTT E300 AI module, based on the Changjiang SoC, provides 50-TOPS-class local compute and can be directly embedded into robot terminals. It supports low-latency, highly reliable real-time responses. In other words, the edge module turns the experience learned in the cloud into immediate robot reactions.
This creates a more complete closed loop: the cloud handles large-scale training and parallel simulation; MT Lambda handles policy development, data synthesis, and simulation validation; and the E300 AI module brings the trained results to the robot terminal for execution.
What matters even more is that Moore Threads’ lineup has already entered real ecosystem validation.
For example, in collaboration with Zhipu, RoboBrain 2.5 completed end-to-end training on a thousand-card MTT S5000 cluster. Related validation results showed that its training loss curve was highly consistent with that of the H100 cluster, with only a 0.62% difference, and in some tasks it even performed better. In addition, scaling the cluster from 64 cards to 1024 cards achieved over 90% linear scaling efficiency.
These results show that domestic computing clusters are already practical as a foundation for embodied model training.
The collaboration with Guanglun Intelligence is more geared toward mass-producing simulation data. Based on Moore Threads’ full-feature GPU and the KUAE cluster, the two sides combined Guanglun Intelligence’s integrated “solve — measure — generate” simulation platform to jointly build a highly reliable simulation data synthesis solution. Guanglun Intelligence’s high-precision GPU physics solver is compatible with the MUSA architecture and can simulate complex physical processes such as rigid bodies, soft bodies, fluids, and particles with high precision and in real time. In related cases, the simulation accuracy for core physical parameters has exceeded 99%.
The collaboration with Pony.ai extends the scope into autonomous driving. Based on the MTT S5000 and the KUAE cluster, the two sides are adapting and validating world models and in-vehicle model training. Pony.ai’s world model can generate more than 10 billion kilometers of test data per week, from which many extreme scenarios are derived. For autonomous driving, long-tail scenarios, extreme hazards, and safety validation are precisely where simulation is most valuable.
In addition, Moore Threads is working with partners such as May 1 Vision and Guangxian Cloud to build physical-AI simulation systems and embodied simulation platforms. Whether it is 4DGS model training and inference, synthetic data generation, task libraries, simulation computing, or virtual-real validation loops, they are all essentially answering the same question: embodied AI cannot be built by a single company alone. It takes compute infrastructure, simulation, algorithms, and scene providers working together for the ecosystem to function.
That is probably the most important takeaway from Moore Threads’ announcement this time.
It moves the story from “I have one chip” to “I can build an entire foundational infrastructure stack.”
By building platforms on top of the MUSA architecture and full-feature GPU base layer, connecting to the edge, and expanding outward into the ecosystem, this approach may not redraw the industrial map overnight, but it does push domestic GPUs one step further—from large-model training and inference toward the foundational infrastructure of physical AI.
The Goal Is a Domestic Embodied AI Infrastructure Stack
One of the biggest contradictions in embodied AI today is that models are evolving fast, while scenarios are lagging behind.
In the digital world, large models can keep improving on the back of massive text, image, and video data. But in the physical world, every time a robot opens a door, carries a box, grasps a soft object, or navigates a complex intersection, there is a real cost behind it all.
Real-world data collection is expensive, teleoperation is slow, equipment damage is risky, dangerous scenarios cannot be tried casually, and long-tail cases are impossible to fully cover. That is why simulation-synthesized data and the Sim-to-Real closed loop have become the key infrastructure that allows embodied AI to move from the lab into industry.
That is why “building the world” becomes the central challenge in embodied AI competition.
And the value of that world is not that it looks good like a game. It is that it can train robots, validate them, and correct their behavior. It needs enough realism to reflect lighting, materials, collisions, friction, and sensor noise, and enough efficiency to generate data at scale in parallel. It also needs openness, so different models, robots, and scenes can connect to it.
From this perspective, Moore Threads’ strength is not something that can be explained by a single performance number. Its “full-feature GPU + MUSA ecosystem” strategy is fundamentally well aligned with the complex demands of embodied AI.
Full-feature GPUs provide capabilities across AI compute, graphics rendering, physics simulation, scientific computing, and video codecs. MUSA provides a unified software ecosystem. MT Lambda integrates physics, rendering, and AI engines. The KUAE cluster handles large-scale training and simulation. The Changjiang SoC and E300 AI module bring those capabilities to the edge. External ecosystem partners complement the stack with data, scenes, simulation platforms, and industrial applications.
The value of this entire flow lies in the fact that embodied AI is, at its core, systems engineering.
Large-model companies may first compete on the strength of their digital brains, but robot companies ultimately face a different set of questions: how does the brain control the body, how does the body understand the environment, and how can the environment be reproduced at low cost? Whoever can build a training world that is cheaper, more efficient, realistic enough for robots, controllable enough, and large enough is more likely to take embodied AI from demos into real production lines, roads, homes, and urban spaces.
Of course, building a domestic embodied AI infrastructure stack will not happen overnight.
The realism of simulation, the effectiveness of Sim-to-Real transfer, the maturity of the developer ecosystem, and adoption by industrial customers all require ongoing validation. How far Moore Threads’ solution can go will depend on more real-world projects, more developers, and feedback from more robots in the future.
But at the very least, this launch shows that domestic GPUs have entered a new stage.
They are moving beyond the passive story of “can it replace that card?” and beginning to define new computing scenarios on their own. The “Wheat” upgraded at the event is a digital agent, while the robot dog “Xiaofei” that performed a backflip is a physical agent. As AI moves out of the screen and into reality, and agents become able not just to “talk” but to “move,” foundational compute must understand models, graphics, and physics at the same time.
At the event, Zhang Jianzhong said that Moore Threads wants its products to span from KUAE to Changjiang, supporting every kind of intelligent agent.
In the context of embodied AI, that can be put more concretely as follows: the cloud has large-scale training grounds, simulation has virtual worlds, the edge has execution capability as a “small brain,” and the ecosystem has real-world scenarios.
If the large-model race is about who can train the stronger digital brain, then the embodied AI race adds another question: who can be the first to build a sufficiently realistic training world?
This time, domestic GPUs have clearly begun to enter that world-building race in earnest.