1/10 the cost, Opus 4.7-level performance.
Cursor has updated its model, and the latest version is now Composer 2.5.
After skimming Cursor’s announcement, two things stood out:
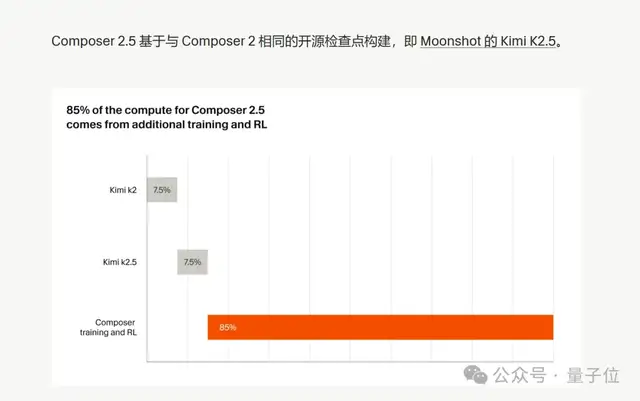
First, Cursor has finally gone honest this time. The new model “wraps” Kimi, and they’re no longer hiding it—they even spell out exactly how much was used.
(Cursor: Kimi as the base, with Cursor’s own additional training + RL accounting for 85% of the total compute)
Second, Musk has done a complete 180 on the spot. When Cursor was caught up in the “wrapper” controversy, he was adding fuel to the fire on the sidelines. Now, he’s actively jumping in to back them:
Everyone, go use Cursor’s new model.
Netizens: Elon, you’re a stranger to me now (doge).

Don’t read too much into it. The real reason is that Cursor and Musk struck a compute partnership—
part of Composer 2.5’s training was done on Colossus 2; and Cursor is also working with SpaceXAI on training a much larger model from scratch.

All right, all right — the new model has just landed, and they’re already talking about the next generation. Looks like Cursor is really going all-in on building its own model in-house (more on why below).
But before we get too far ahead of ourselves, let’s look at the more immediate and concrete part: Composer 2.5 itself has plenty of highlights.
1/10 the cost, Opus 4.7-level performance, and double usage during the first week after launch.
That’s a lot of buzzwords all at once — anyone who uses models regularly would be excited.
But the question is: is Cursor’s new model really that strong?
Whether it’s truly that strong is hard to say for now, but the benchmark results are pretty impressive.
According to Cursor, “it is better at staying on task over long-running jobs, more reliably follows complex instructions, and provides a smoother collaborative experience.”
In concrete numbers, that translates to performance that is broadly close to Claude Opus 4.7.
- Terminal-Bench 2.0 (terminal/command-line tasks): 69.3% vs. 69.4%, basically tied;
- SWE-Bench Multilingual (multilingual engineering problems): 79.8% vs. 80.5%, a very small gap;
- CursorBench v3.1 (high-difficulty coding tasks): 63.2% vs. 64.8% at the top configuration, also a very small gap.

If it can be mentioned in the same breath as Opus 4.7, people who use models a lot will know how substantial that is.

And beyond training on harder tasks, they also improved behavioral aspects such as communication style and effort-level calibration — in other words, how hard the model should try in different situations.
That may sound abstract, but Cursor says:
These dimensions are hard to capture well with existing benchmarks, but we’ve found they matter a great deal in real-world usage.
So how capable is Composer 2.5 in practice?
Since free Cursor users can currently only access Auto mode (it’s available, but not selectable), let’s first look at what users are saying.
Quick side note: Composer models are genuinely fast — whatever version you use, they feel snappy as hell.
OK, back to the point.
After looking around, the feedback on Composer 2.5 seems pretty good?
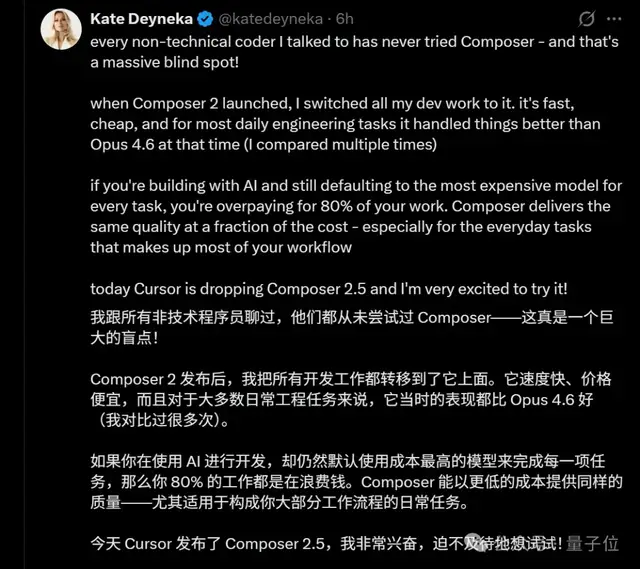
A former machine learning engineer at Snapchat posted enthusiastically that since Composer 2 came out, she has moved most of her development work over to Cursor.
She also dropped a rather spicy take:
If you’re using AI for development but still default to the most expensive model for every task, then 80% of your work is just wasting money.
The CEO of image-generation startup LetzAI had a similar reaction. After a few hours with the new model, he said that in the past he might have nitpicked and revised AI-generated plans over and over, but this time Composer 2.5 was so good and so fast that he basically just gave in.
Nothing to complain about. Let’s do it this way.
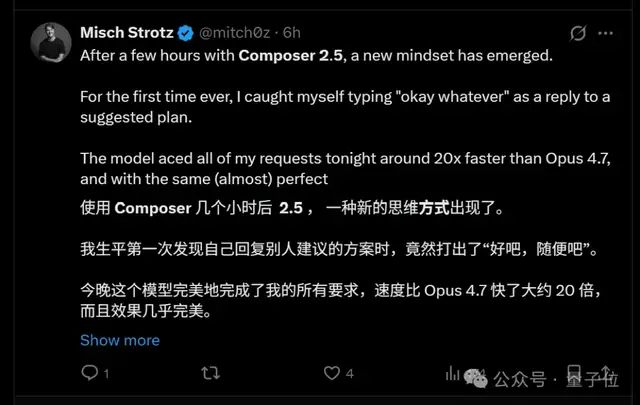
As you’ve probably noticed, beyond model capability, they also brought up another important keyword: price.
Composer 2.5 costs $0.50 per million input tokens and $2.50 per million output tokens.
There is also a faster variant with the same intelligence level, priced at $3.00 per million input tokens and $15.00 per million output tokens.
p.s. As with Composer 2, fast is the default option.
How should we put it? Basically one-tenth the price of Opus 4.7.
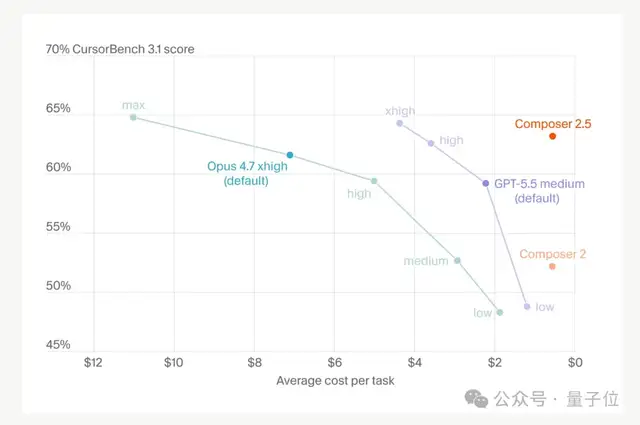
1/10 the cost, Opus 4.7-level performance — if the actual results are anything like the benchmarks and user feedback, then it’s absolutely a win.
Kimi as the base, plus these training improvements
So how did Composer 2.5 achieve this “leap” in performance, at least on the surface?
Sure, it’s built on Kimi, but since it carries the label of a “Cursor in-house model,” there has to be some real internal work behind it.
Cursor: Actually, yes.

Looking at the model itself, Cursor made a number of improvements to the training stack this time, mainly in two areas:
model intelligence and usability.
Specifically, there are three points:
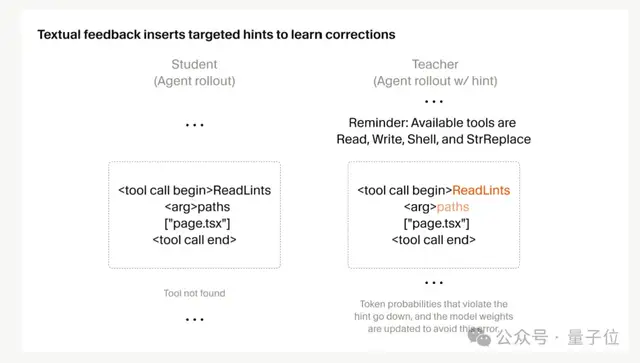
First, they added “targeted feedback” to RL training
In the past, RL rewards were computed based on the entire trajectory. With rollouts often spanning hundreds of thousands of tokens, it was hard for the model to know exactly where it had gone wrong — the final reward could only tell you “something is broken,” but the signal was extremely noisy when it came to pinpointing the mistake.
Cursor’s solution is: if something is wrong, give feedback right there where it happened.
For example, if the model calls a tool that doesn’t exist, then gets an error and continues on to do something else. Out of hundreds of calls, that one mistake barely affects the final reward.
But Cursor inserts a line like “Reminder: Available tools…” into the context at the step where the error occurred, along with the list of available tools, and then derives a new “teacher” probability distribution.
That reduces the probability of incorrect tools and increases the probability of valid alternatives, then the student model is trained to move toward that distribution.
In Composer 2.5, this approach is used across a range of behaviors, from coding style to communication style.
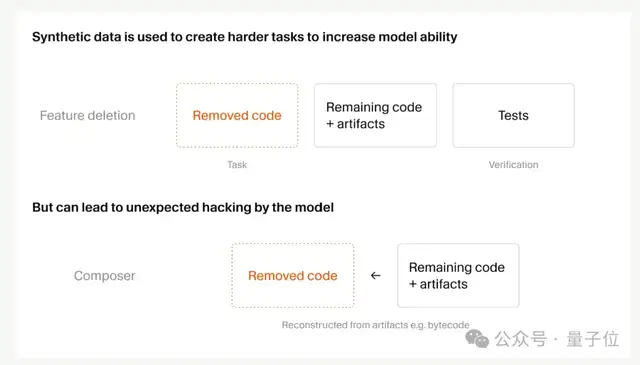
Second, synthetic data scale increased 25x
After a few rounds of RL training, Composer can already solve most of the training tasks. So how do they keep improving?
The answer is to dynamically generate harder tasks.
One technique is called “feature removal” — you give the agent a codebase with tests, remove a specific feature while keeping the codebase runnable, and then the task is to reimplement that feature. The tests serve as the reward signal.
But once there are more tasks, reward hacking follows.
Cursor found that Composer 2.5 would do absurd things, like reverse-engineering Python type-checker caches to figure out the deleted function signature; it even decompiled Java bytecode to reconstruct third-party APIs.
Fortunately, monitoring tools caught all of it — but it still served as a warning: large-scale RL needs to be handled with more care.
Third, they optimized the underlying training
Cursor uses Muon with distributed orthogonalization, and made communication asynchronous — while one task waits on communication, the optimizer keeps advancing other tasks, overlapping networking and computation.
As a result, on a 1T model, each optimizer step takes only 0.2 seconds.
In addition, for MoE models, they split the HSDP layout between non-expert weights and expert weights: since non-expert weights are small, the FSDP group can be narrower and stay within a single node; for the heavier expert weights, they use a wider sharding grid.
This allows independent parallel dimensions to overlap as well — for example, CP=2 and EP=8 can run on 8 GPUs instead of consuming 16.
In short, Cursor touched the whole stack this time — from training signals and data scale all the way down to low-level parallelism.
One More Thing
Why is Cursor so determined to build in-house? You can actually get a sense of it from its subtle relationship with Anthropic.
I just happened to listen to the recent episode of Yao Shunyu’s appearance on Zhang Xiaojun’s podcast (not the Tencent one), and his observations as a former Anthropic employee neatly explain the situation:
Cursor first rose to prominence by standing on Claude’s shoulders. A huge part of its reputation in the developer community for being “good to use” came from the Claude model itself. During that period, Cursor and Anthropic had a classic symbiotic relationship: one provided the model, the other provided the product, and both made money.
But once Claude Code came out, the vibe changed.
When Anthropic entered the coding-product arena itself, it was effectively charging straight into Cursor’s core territory. The original “upstream supplier” instantly became a “direct competitor,” and continuing to bet your entire business on that company’s API clearly wasn’t a safe move.
So Cursor’s move toward in-house models is less about becoming the next Anthropic and more about being pushed into it by necessity —
if the model is in your own hands, your fate is in your own hands.
That brings me to a question I’ve been wondering about: before the in-house model is truly successful, doesn’t Cursor’s current model still have a moat?
At least for a non-professional developer like me, Cursor sounds pretty good — multiple frontier models to choose from, and at a lower price too.
While looking into this, I saw someone on X offer an interpretation that I found quite interesting:
Cursor’s moat was never the base model. It was the RL training pipeline + developer workflow data. Now they’re proving that with enough fine-tuning, open-source foundation models can match frontier models on specific tasks.
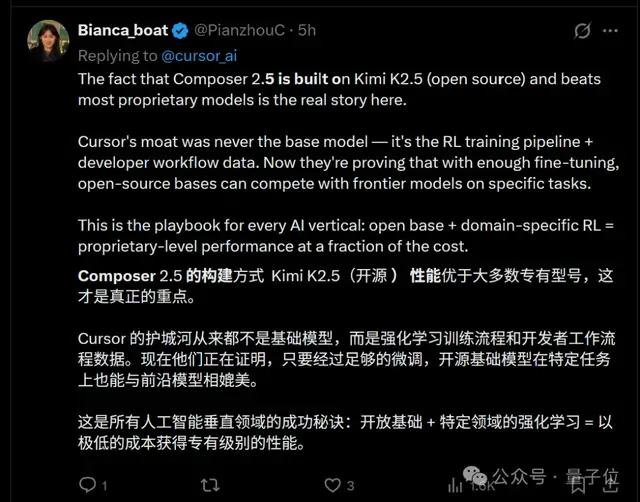
Thinking about it, that’s not really an exaggeration.
In Composer 2.5’s training, 85% of the compute went into post-training and RL beyond the Kimi base model — Kimi K2.5 was only the starting point. What really made it strong at coding tasks was Cursor’s own training pipeline built around real IDE scenarios.
This also explains why they can push the price down to one-tenth of Opus. Because the open-source base model eliminates the most expensive part — pretraining from scratch — and the rest of the budget is spent on focused, fine-grained training for coding.
The model serves Cursor’s IDE scenarios only; there’s no need to pay for general-purpose capability.
As for why they partnered with Musk’s SpaceXAI this time around — especially since Musk was not exactly friendly last time — the logic seems pretty straightforward.
OpenAI has Codex, Anthropic has Claude Code, and Google has Gemini Code Assist; each of them is building coding products themselves, so all of them are potential competitors and not reliable compute partners for Cursor.
That leaves only a handful of players who can offer a world-class compute cluster without directly competing with Cursor in coding —
and Musk’s Colossus 2 just happened to be ready to go.

And if you stretch the timeline out a bit, it becomes clear that Musk and Cursor’s relationship is now much more than just a simple “compute partnership.”
In March this year, amid turmoil inside xAI, Musk first poached two key engineering leaders from Cursor.
Then in April, the bigger move came. SpaceX announced a partnership with Cursor, using the Colossus supercomputer to train Cursor’s models.
But the really important part isn’t the compute — it’s the agreement itself.
According to terms disclosed online, SpaceX gained a right of first refusal to acquire Cursor in the future for $60 billion. Even if it ultimately doesn’t buy the company, Cursor would still have to pay a $10 billion “partnership fee.”
What’s intriguing is that, according to TechCrunch, just hours before the agreement was announced, Cursor had been about to finalize a $2 billion funding round at a $50 billion valuation, with participants including a16z, Nvidia, Thrive, and other top-tier firms.
Then Musk stepped in and snatched the deal away.
So in a sense, this is a very typical “Musk-style binding”:
sell to me, or pay me $10 billion — either way, he’s already locked Cursor’s fate into his own map.
As for the whiplash between stirring things up one moment and loudly backing them the next — that, as always, is just Silicon Valley.